如下图,从“代数”开始往下选取,中间部分全部都没有识别,这不是个例,好多文档都发生了这样的情况,之前没有。
最近做了可能产生影响的操作有
1.更新了最新版的MN
2.清除了OCR缓存
3.整理了MN碎片
求帮助,极大的影响了摘录。
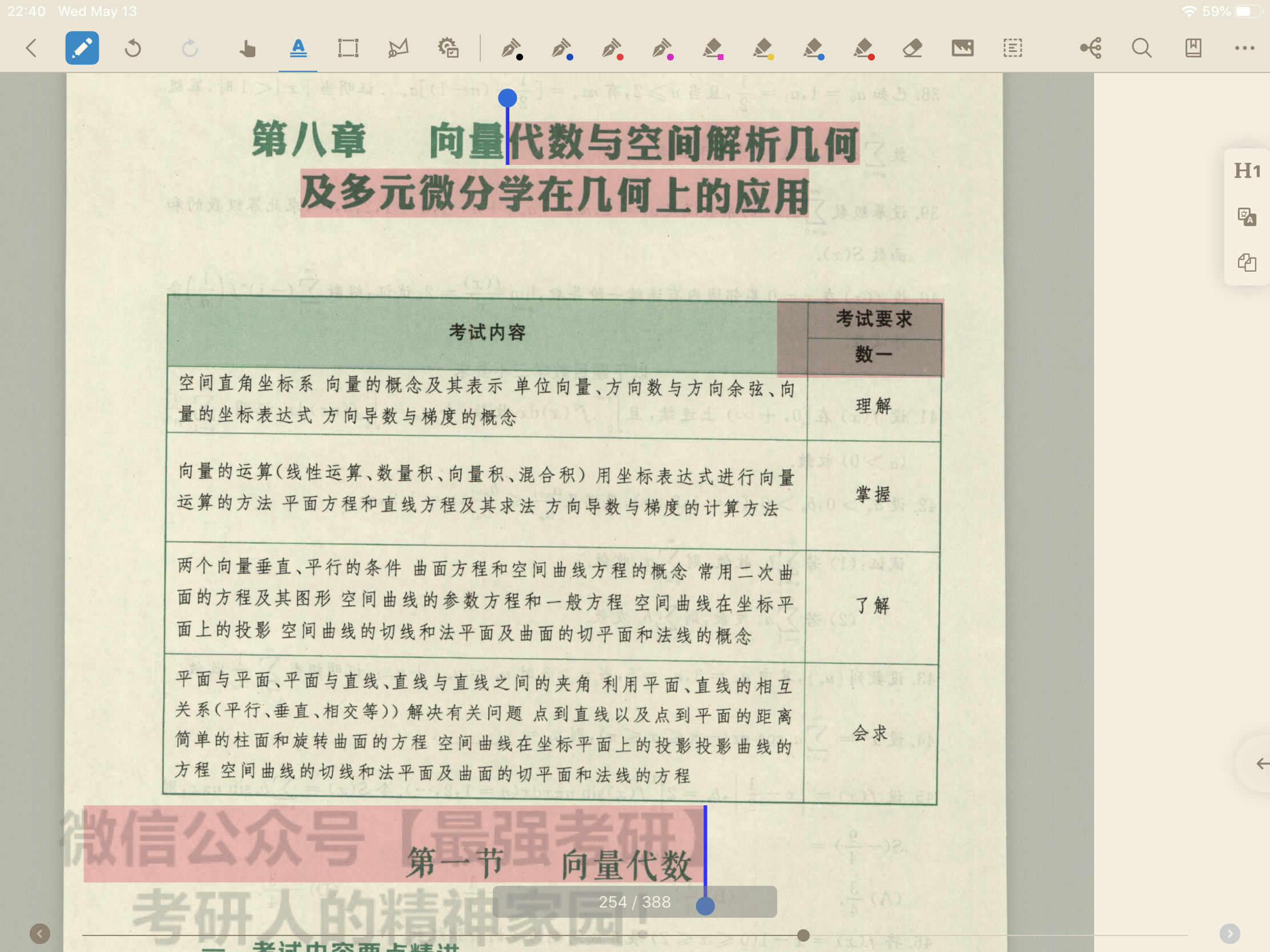
您好,有没有使用OCR Pro 呢?如果没有建议您尝试一下,因为这个pdf有水印所以仅被识别了水印部分。
这也太真实了 
我又做了进一步测试,发现如果完全是图片还是能识别的,如果不是PDF中的内容不是图片,就完全无法识别,更新之前完全是可以的。
请问可以回退版本么,我想回退一下试试。
您好,请将自动选择为“总是”,并选择“英文”看看会改善吗,另外,清理下OCR缓存呢
设置为“总是”,自动,关闭,都试过,语言切换英汉,英语,也都试过。
缓存也清理过,而且清除缓存后,所有的文档全部需要重新识别了。
能将下面的这个文档发我看下嘛
你要源文档么,还是有做笔记之类的文档,这个问题至少在一个星期之前是没有的,而且不是某一个特定的文档,我现在使用的PDF文件,几乎50%~90%以上的内容无法识别。因为主要以PDF为主,现在影响很大。
请问有邮箱么,我可以把源文档发给你,并且发测试视频给你,包括设置等等。影响太大了。。
原因找到了,和留白有关系,你留了很大的空白,所以影响了OCR Pro。由于留白是笔记本局部的变量。所以只有你的笔记本有问题。
不过这个问题,需要时间来解决。这个问题的原因,和设备、RAM都没有关系。目前来说,如果要使用OCR Pro,只能尽量规避使用过大的留白。
所以你先调下留白吧,一时半会儿解决不了
你好,私信里又回复你了
我也有过这样的问题……没那么严重,OCR漏行。
小考拉,你也是有一些留白吗
设置为仅英语呢?
好,我明天试试(今天有点事),试完给你回复。
录直播吗 
不睡觉 我明天凌晨四点有考试
我明天凌晨四点有考试
Hi! :)
我刚才做了一下测试,发现确实如你所说的,仅选中英文之后就没有出现那个问题了;但是如果我选择了中英文,那么问题依然会存在。我测试了好多篇文章,这里就贴一个截图。
以下为图片:
中英文

英文
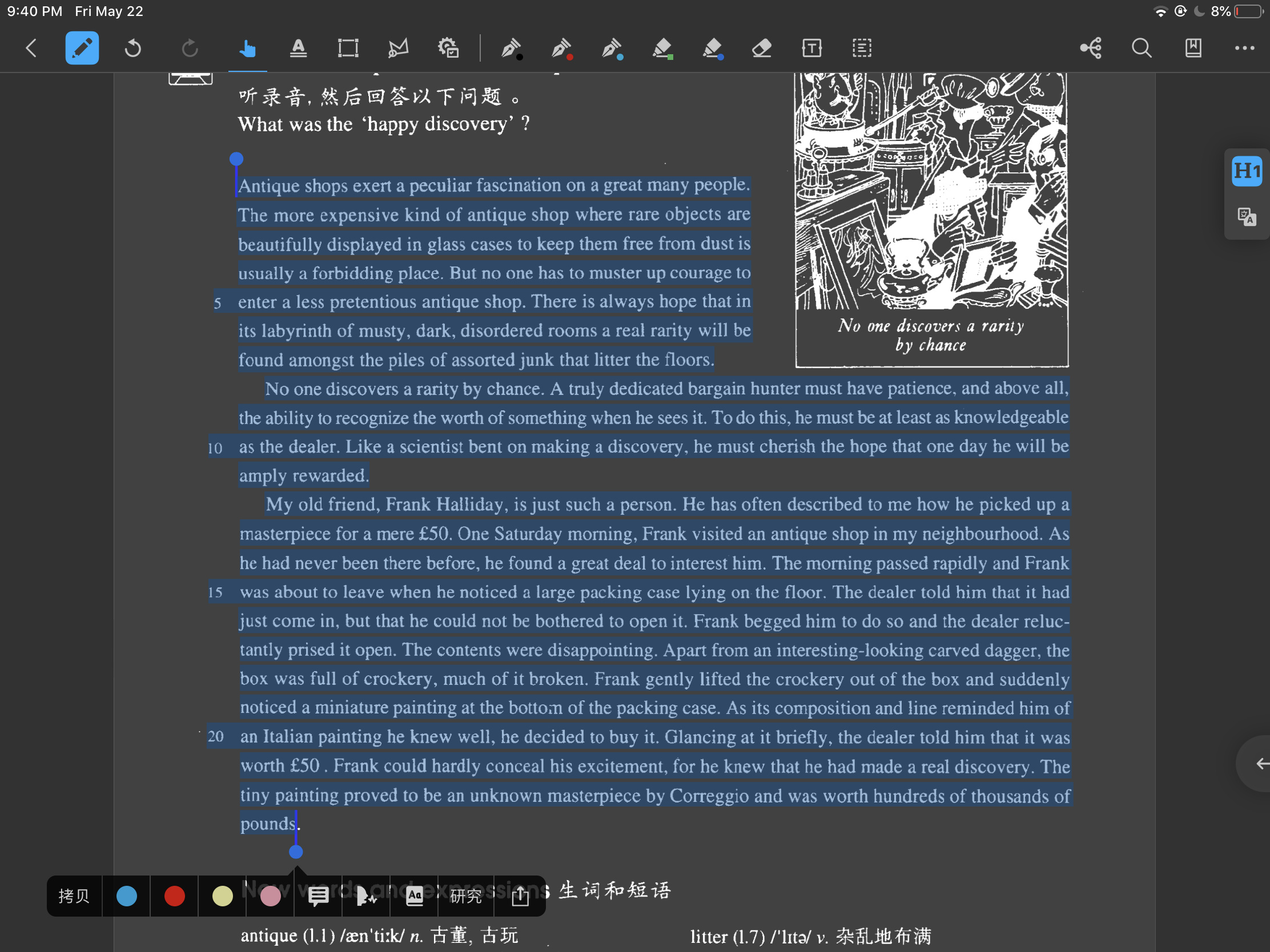
另外,如果需要新概念的这个材料我可以发过来~
嗯嗯,谢谢~
(有的时候如果有只支持中文的选项那就更好了~)