插件反馈
- 如果你对插件有任何反馈,都可以通过以下链接:https://feliks.craft.me/feedback
- 该链接内提供了协作链接,无需登录便可编辑文档
- 也可以加入qq群:539305227
不建议再安装了,有用户安装后存在闪退问题,等待后续修复
插件下载:
所有功能都支持iPad和Mac
除官方签名版本外,安装插件需要在设置中允许“加载未经认证的插件”
安装方式:下载后用mn打开mnaddon文件,或在mn的插件界面导入插件
-
0.0.4
- 跟随MN ChatGLM更新,去除模式选择按钮
- 修复一个小bug
-
0.0.3
- 向量化过程可被取消(点击原更新按钮,会弹出对话框)
- 向量化过程的信息提示优化
- 修改代码逻辑,尽量避免网络错误
- 修复更新时卡片过滤的问题
一、理念
-
所有的笔记软件都存在一个类似的问题,就是内容零散化,我们做了太多笔记,却没有精力去整理,笔记做完了之后就再也不会看第二遍,毕竟思考整理笔记可比做笔记摘录费时费力多了
尽管有人喜欢把个人知识库称为第二大脑,但所谓的第二大脑不应该是把一堆笔记扔进去就算大脑了,并且对笔记的“遗忘”也不是第二大脑所该具有的特征,真正的第二大脑应该是会整理会组织会联想的。你可能会说,这不就是AI吗,ChatGPT看起来就能做这些事。伴随着ChatGPT的横空出世,人们发现大模型好像真的能理解很多东西,好像真的能思考
是的,“会整理、会组织、会联想”这三点说出来容易,要做到就非常难,或许AI能在这方面发挥一点作用,但是如何把MN和AI结合起来呢? -
有人可能会说MN直接搞一个接入类似ChatGPT的大模型就行了,但…
-
把大模型搬到笔记里面是非常不切实际的,其对性能的要求和功耗都不是一个小小的iPad所能承受的,因此软件能做的更多是调用大模型所提供的API,来实现在线的调用
-
个人的笔记是非常个性化的东西,想要得到一个专属于你的AI,需要对大模型进行微调,这比上一点还不切实际,所以普遍方案是把特定文本作为prompt中的参考信息,让AI基于参夸信息进行回答问题,这就又引入下一个问题
-
个人笔记库的数据量非常大,大模型并不能接受过长文本的输入(如ChatGLM的token限制是8k),也就几千个词,一篇论文都容不下,更别说把知识库放进prompt中了
-
-
那么如何在不对模型本身做调整的情况下获得基于个人知识库的回答呢?
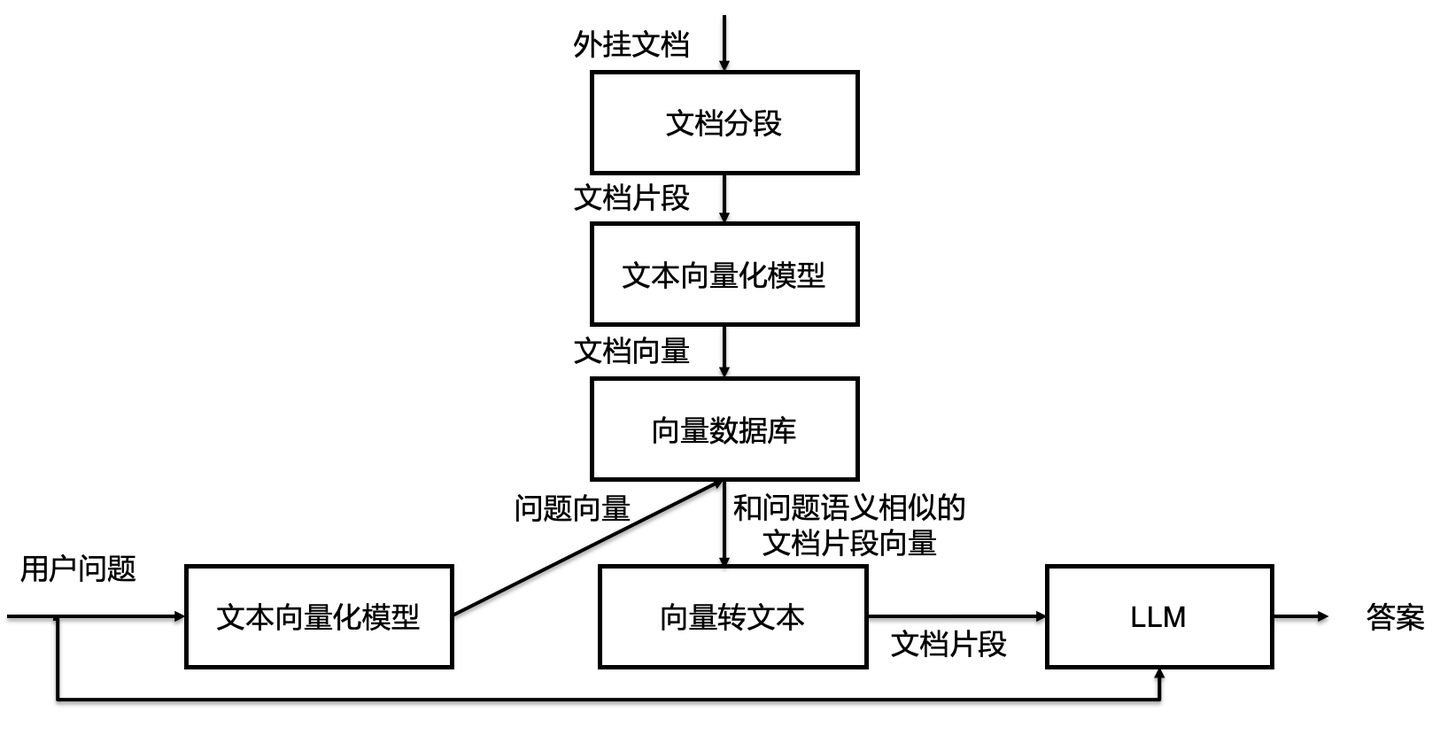
一种方法是外挂知识库,原理如下图所示:这里需要提到一个概念:文本嵌入方案(text-embedding),即将文本转化成一个高维向量,这个向量就代表着这段文本的语义。这个转换过程我称为向量化(vectorize)
自然,向量数据库中存放着的就不是传统的文本了,而是一个个高维向量,每个向量对应一段原始文本
我们可以将用户的问题向量化后在向量数据库中寻找高相关的向量,对应到其文本片段,并加入prompt中作为上下文,并让AI基于上下文回答问题 -
原理明白了,那上哪弄向量数据库呢,或者说,既然MN的笔记本本来就是以卡片为最小单位的,那么我们能不能直接把MN的笔记本做成一个向量数据库呢,这样AI就可以基于整个笔记本(甚至整个MN里的所有笔记)来回答问题了,这样是不是就得到了一个专属于你的AI?
答案当然是可以(不然也不会有这个插件) -
除了上面提到的功能外,基于向量数据库我们还可以做一件更具体的事,就是帮助发现卡片之间的关联,也可以理解为AI进行的联想:
- 对于给定的卡片,在向量数据库中寻找相关性高的卡片
- 将相关性最高的部分卡片展示出来,并提供一系列操作
-
这也正是本插件的核心部分:创建向量数据库+AI联想,也对应了前面提到的大脑的“知识输入+联想”,而“思考和总结”则由AI对话的部分完成
利用ChatGLM提供的文本转向量的服务,我们就可以把MN 卡片的每段文本都转化为对应的向量,从而创建一个专属于你的向量数据库

二、使用方法
-
获取API并填写
(参考MN ChatGLM插件的API获取部分)
因不明原因,建议第一次安装的用户,粘贴完API-key之后,重启一下软件
否则有可能更新卡片时无反应(即使是网络问题也会在一分钟之内弹出“error”),如果一点反应都没有,重启之后有概率自己就好了 -
建立向量化数据库
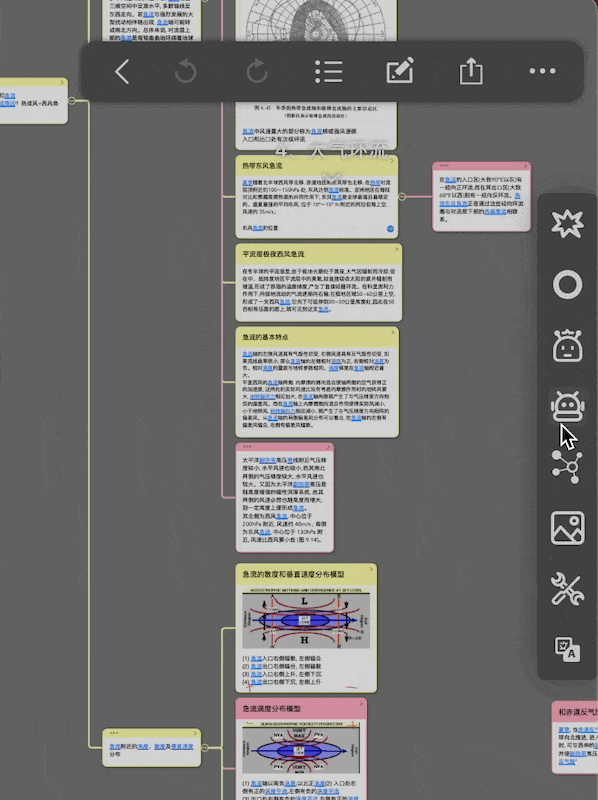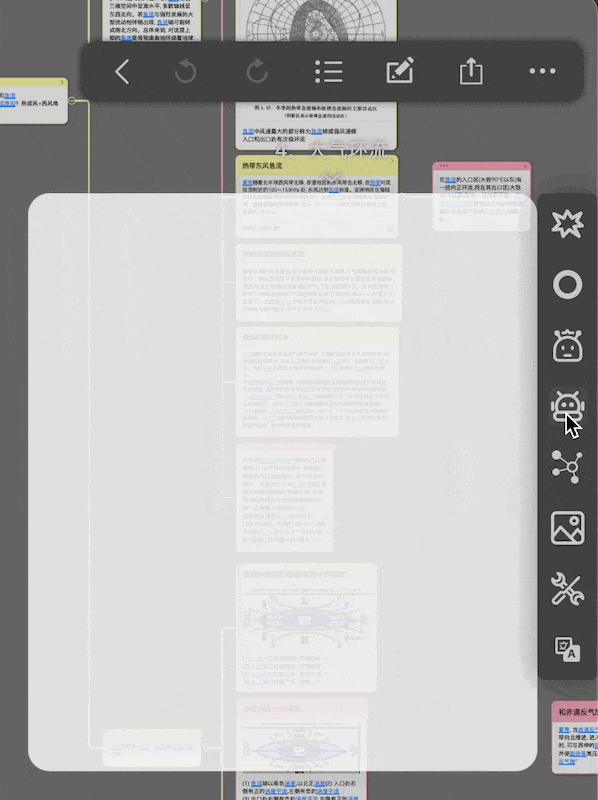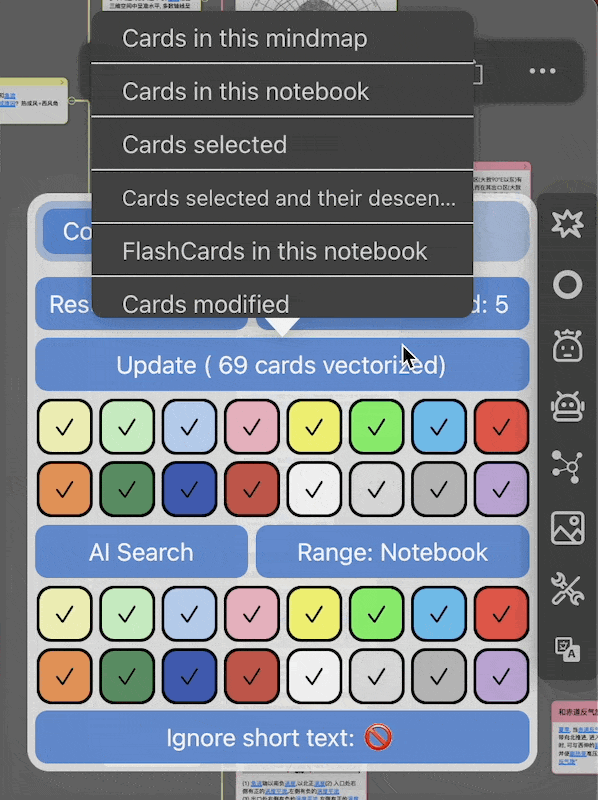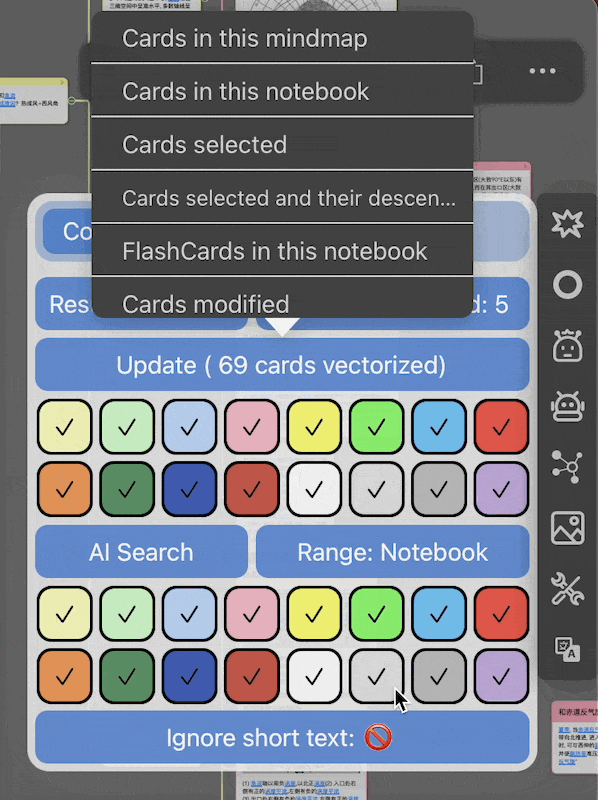
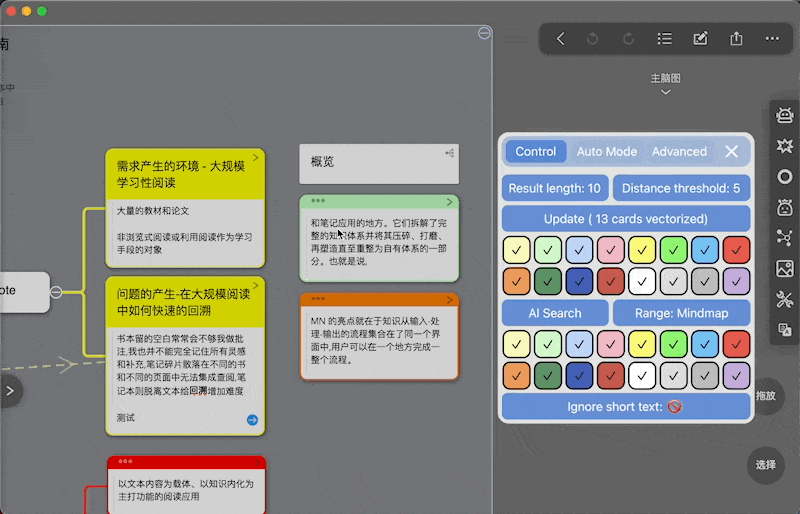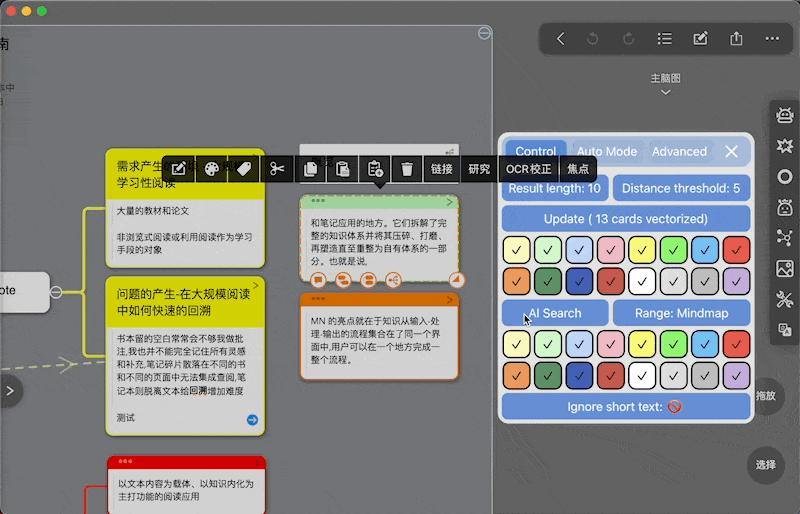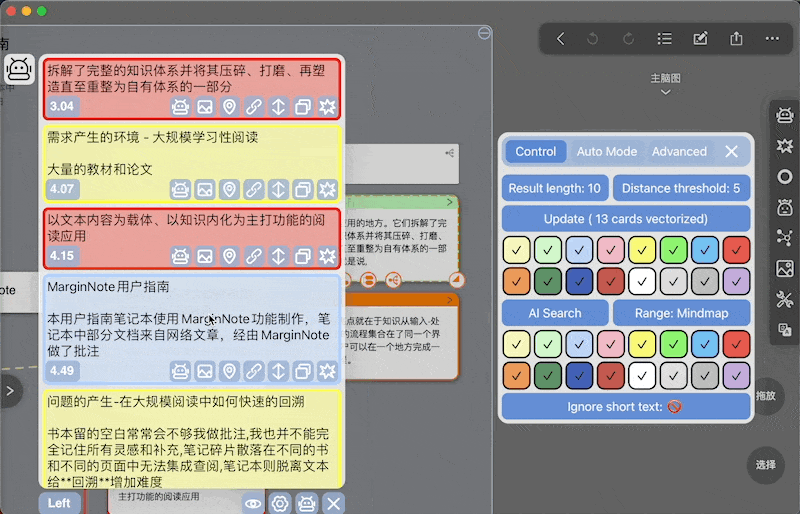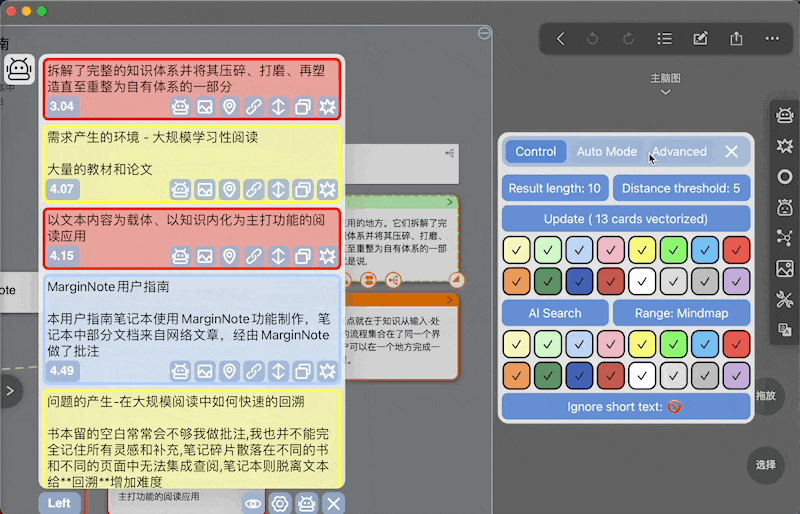
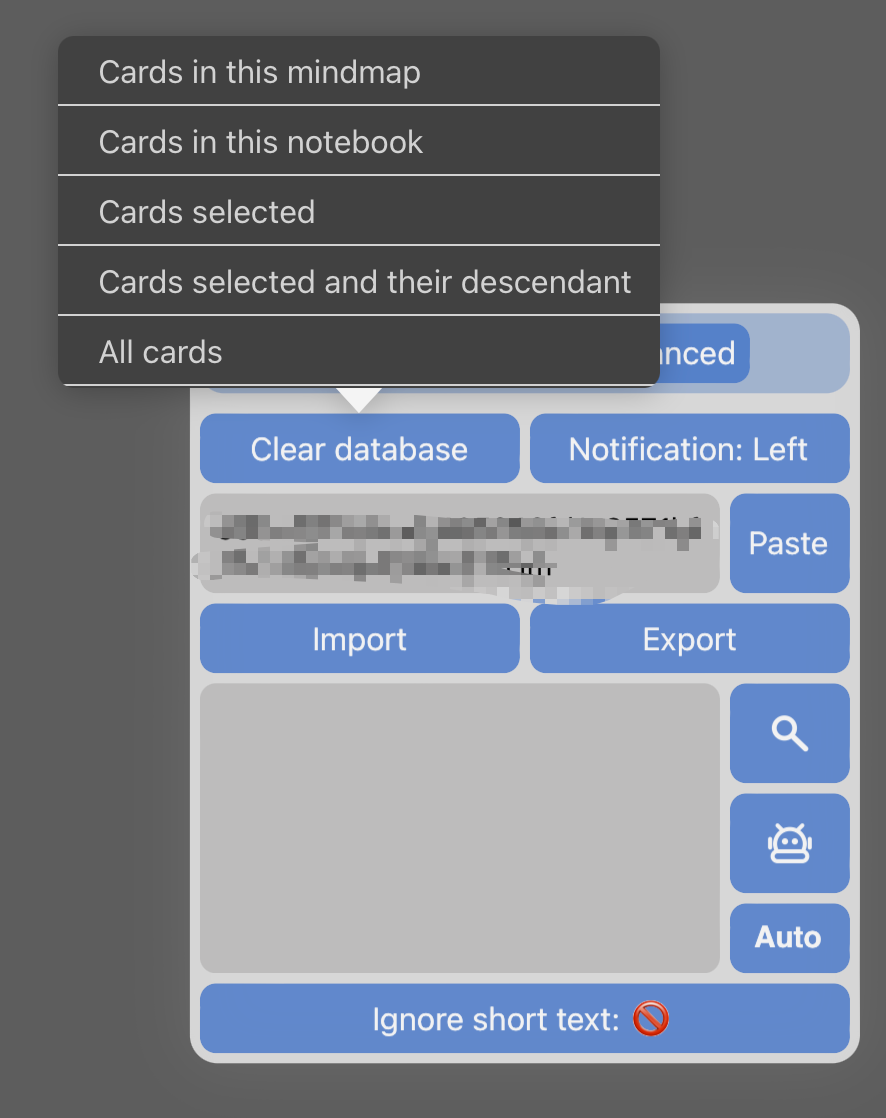
点击插件logo,从插件栏弹出控制面板,点击update,选择需要更新的范围,并等待处理结束
这里把对每一张卡片创建向量的动作称为向量化(vectorize),对向量数据库的创建/修改提供六个选项
mindmap:当前脑图的卡片,不包括子脑图里的
notebook:当前笔记本的所有卡片
selected:选中的卡片
selected cards and their descendant:选中卡片极其后代的所有卡片
flashcards:当前笔记本中所有被添加到复习的卡片
cards modified: 已经向量化的卡片中被修改过的部分
- 颜色过滤:前两排颜色方块指要对选中范围的哪些颜色的卡片做向量化,默认全部颜色

-
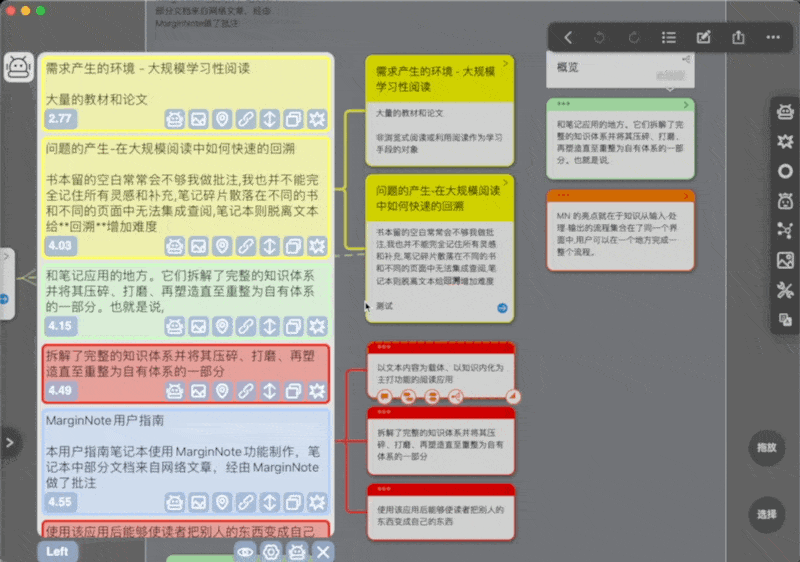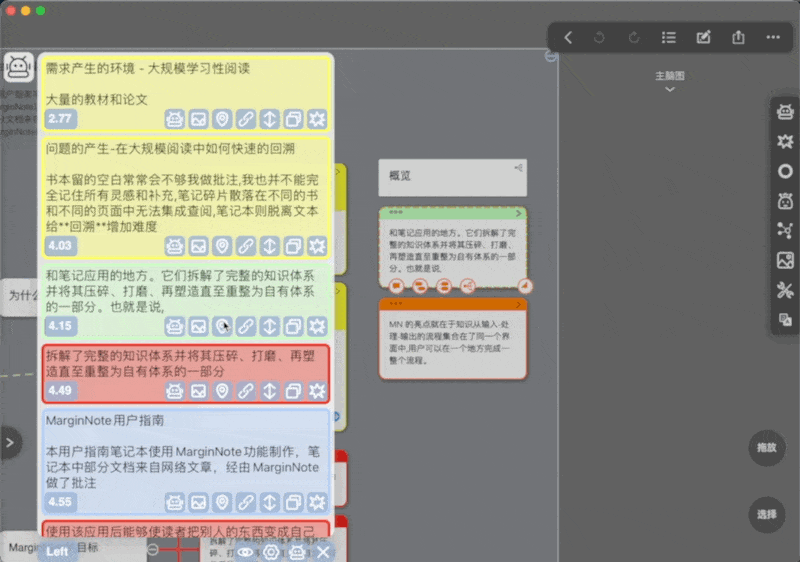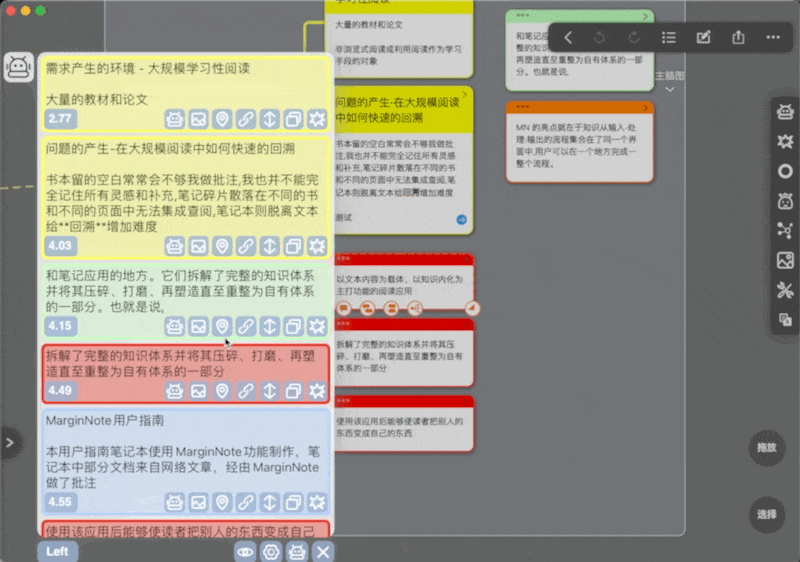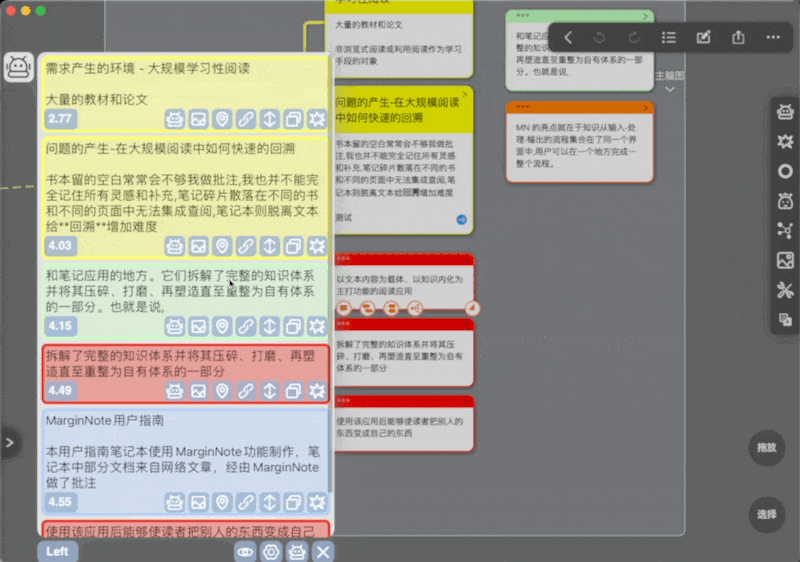
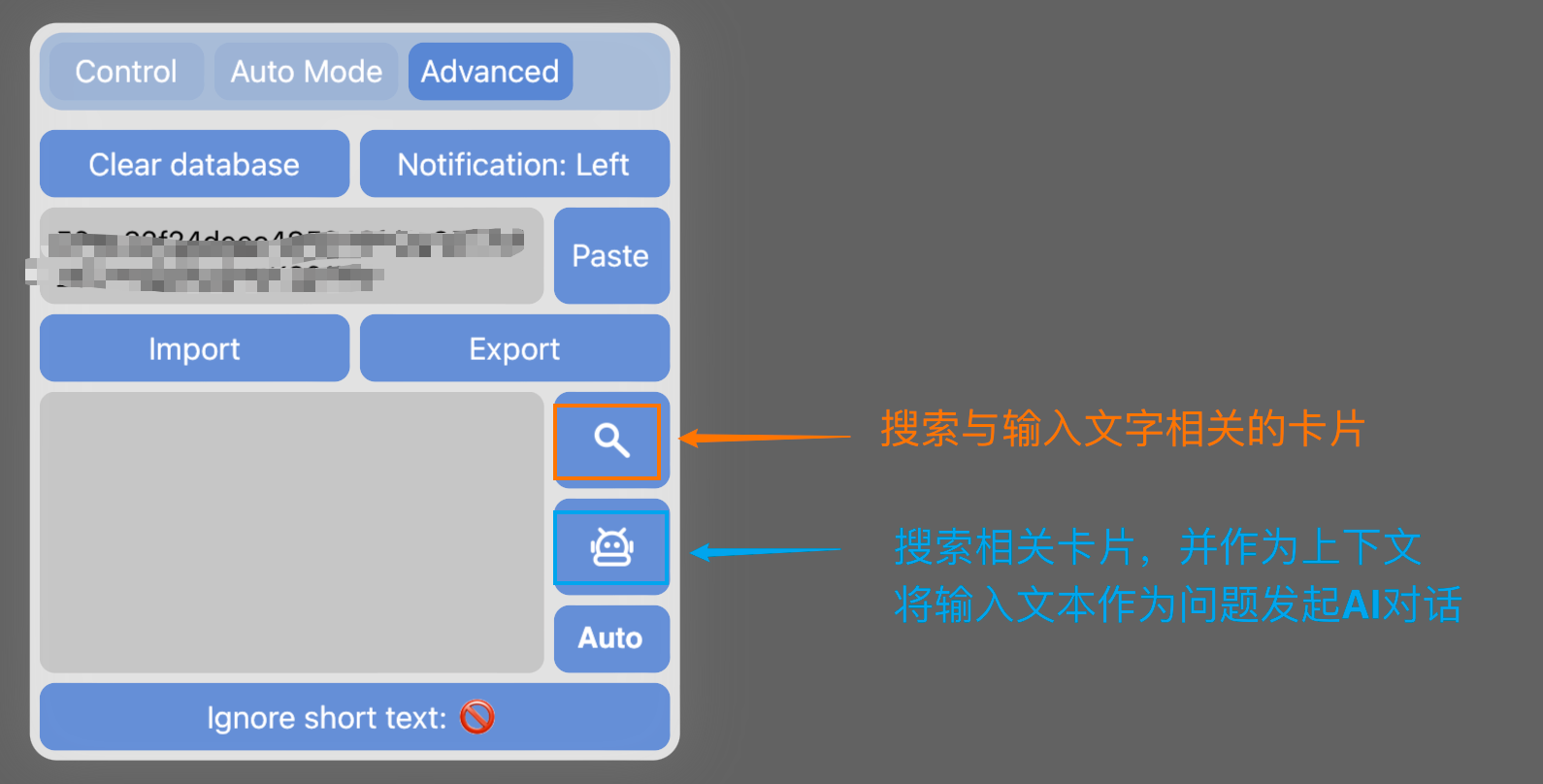
搜索相关卡片
卡片搜索可由三种方式触发,执行结果都是从左侧或右侧出现窗口(没有相关卡片就不弹出窗口),窗口中相关卡片以距离从小到大排序(对应着和中心卡片的相关从高到低)
下图后两排颜色方块指要获取的卡片的颜色范围
最后一个
Ignore short text开关:- 更新卡片时指是否忽略过短文本(10个汉字/单词)
- 搜索时是否忽略文本过短的卡片
选中卡片,点击AI Search
选中卡片,双击插件logo
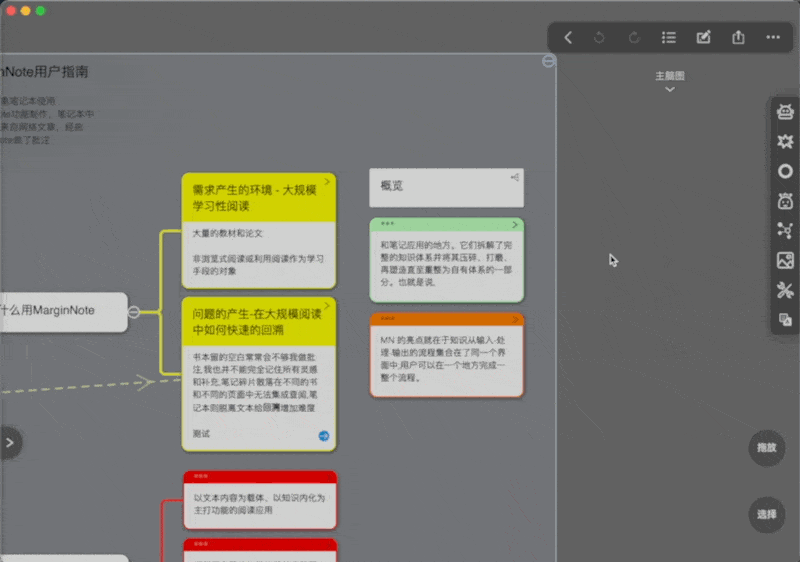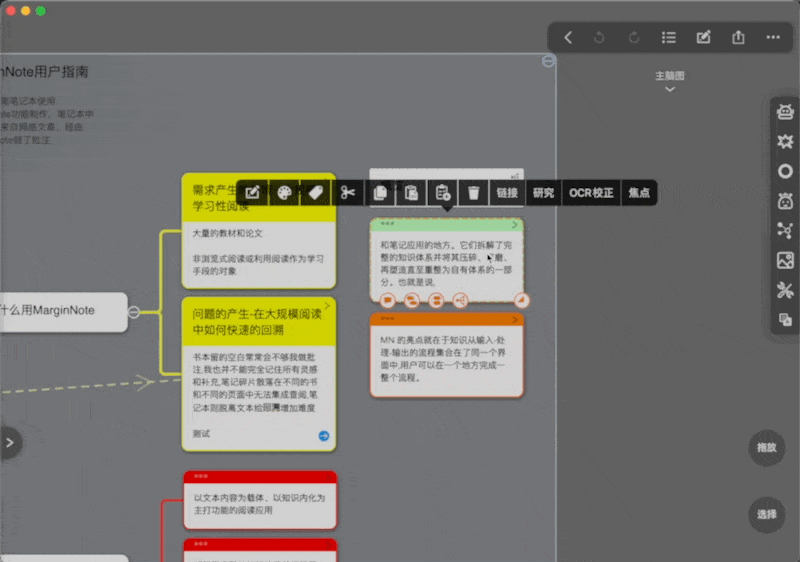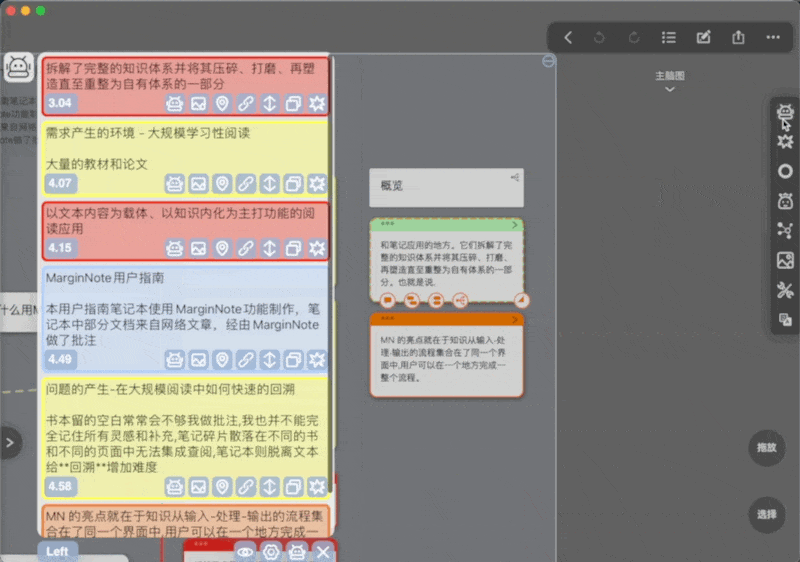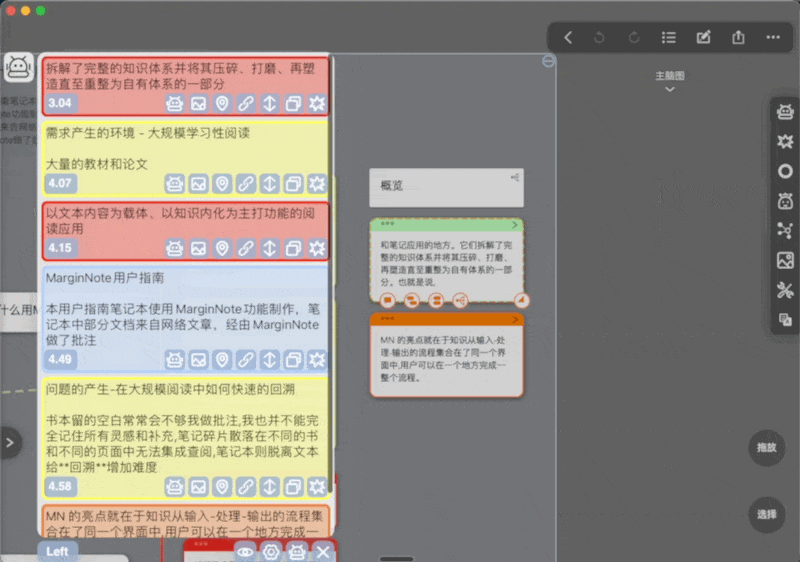
选中卡片,然后点击窗口右下角的按钮
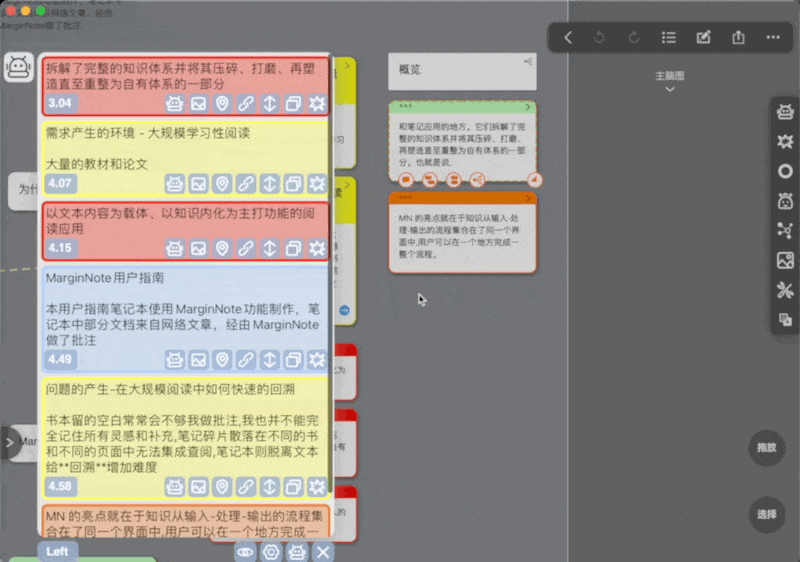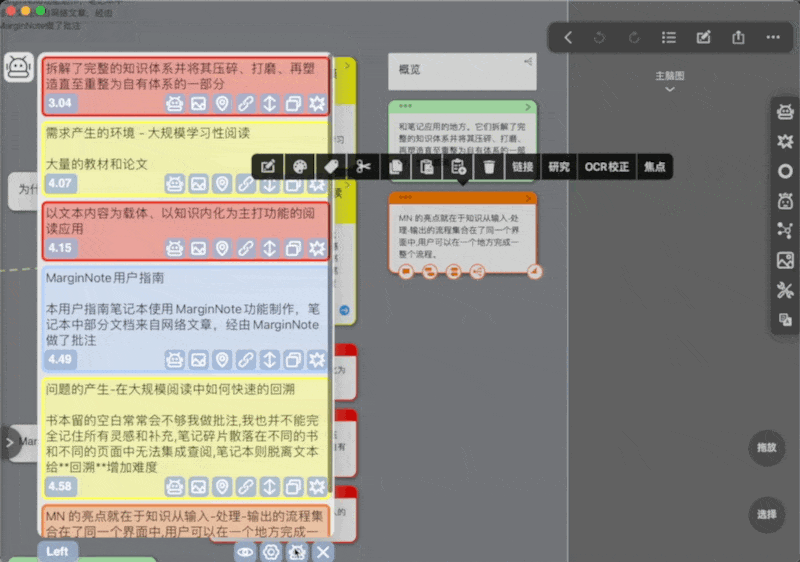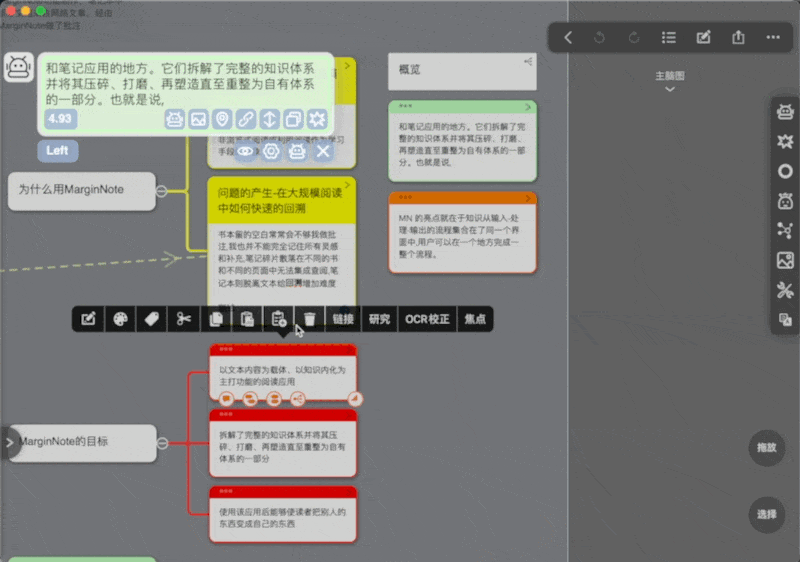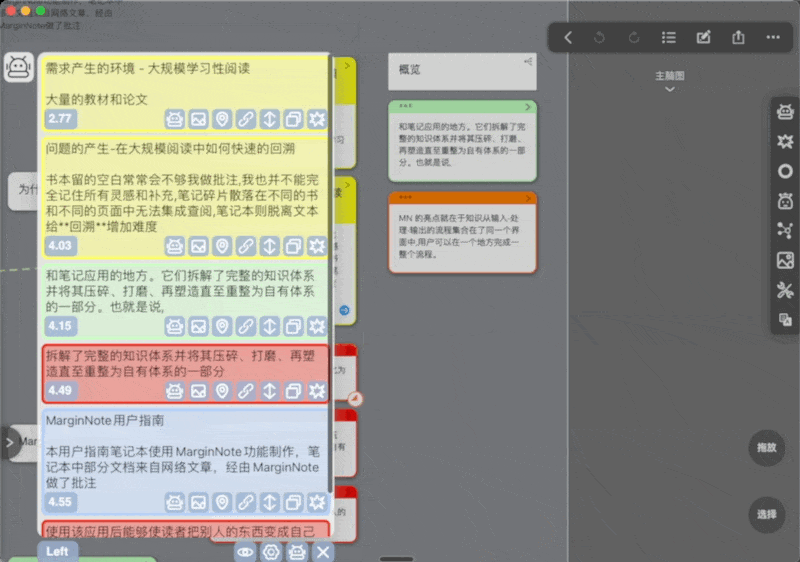
部分按钮介绍
-
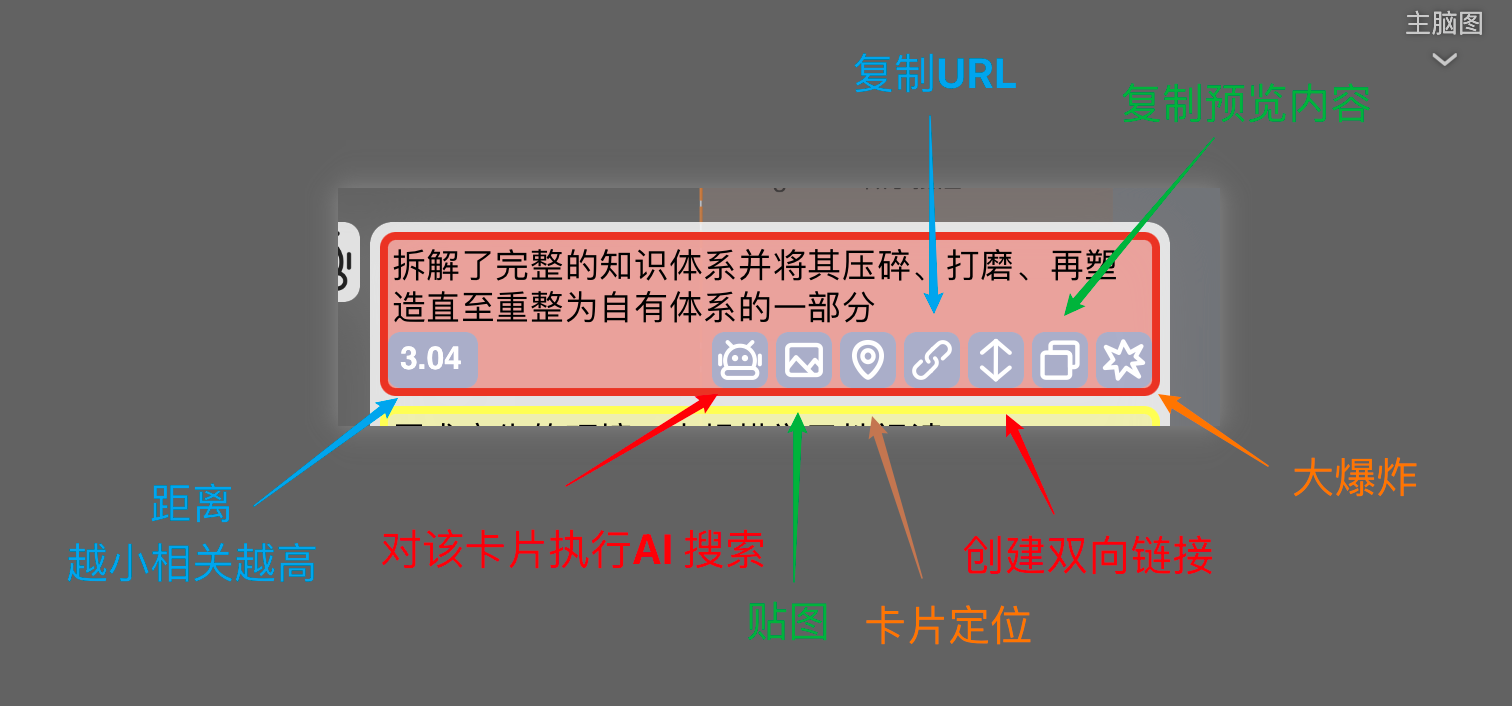
可以看到每个卡片预览下都有一堆按钮
-
窗口最下方的眼睛为聚焦按钮,即定位到当前卡片的位置,这样你就可以在相关卡片和当前卡片之前来回跳转(对于不同子脑图间的卡片尤其有用),但是不允许不同笔记本之间的跳转,只会告诉你在哪个笔记本
-
滚动到页面底部会看到一个“more”按钮,点击会显示更多相关卡片
如设置中“Result length"设置为10,则点击此按钮后会再多显示十条,若已经没有更多相关卡片,则按钮消失

三、自动模式
-
自动模式默认关闭,开启后会在点击卡片/创建新摘录时自动搜索相关卡片,插件logo进入高亮状态
- 建议将距离阈值调低,这样可以做到仅在发现高相关卡片时通知
- 这里的
Ignore short text开关指当卡片文本过短时,是否直接忽略该卡片 - 而“搜索时忽略文本过短卡片”则依然由Control面板里的
Ignore short text开关控制

四、搜索与问答(实验性)
-
基于当前卡片列表的问答可在卡片列表窗口直接进行,调用MN ChatGLM实现
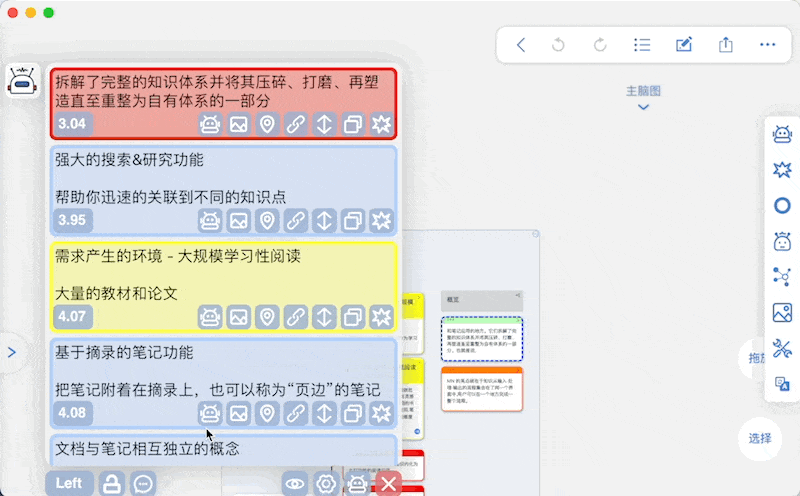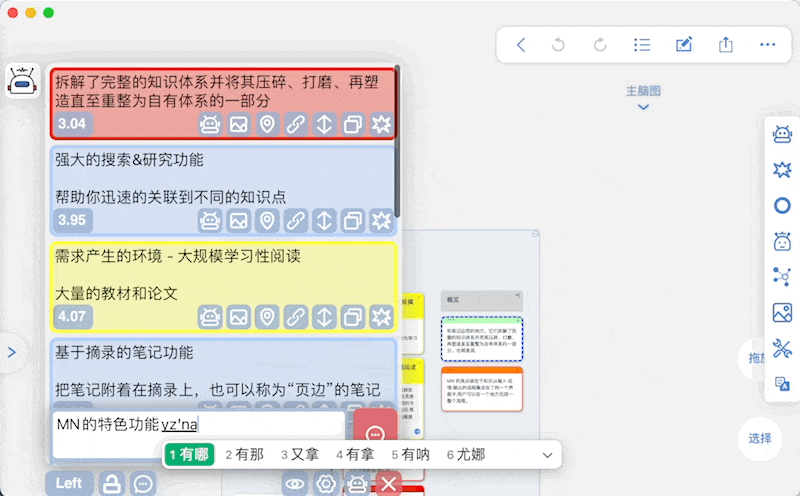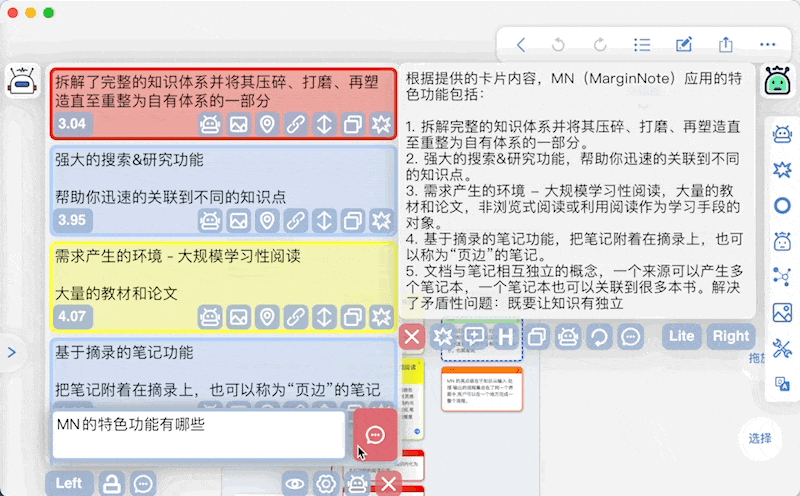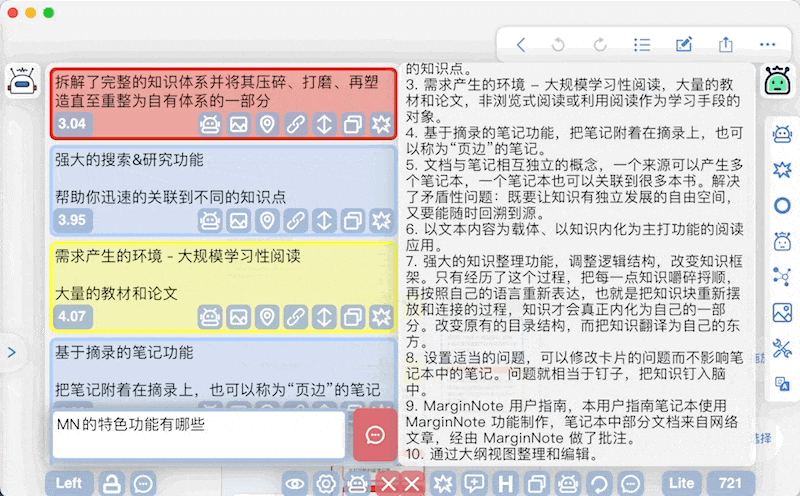
-
另外本插件支持对卡片内容的模糊搜索,作为实验性功能放在Advanced面板中
原理就是把输入的文本向量化,然后在数据库中搜索相关的卡片
同时支持问答:在搜索的基础上直接把搜索到的卡片作为上下文,输入的文本作为问题,发起AI对话 -
举个
 :
: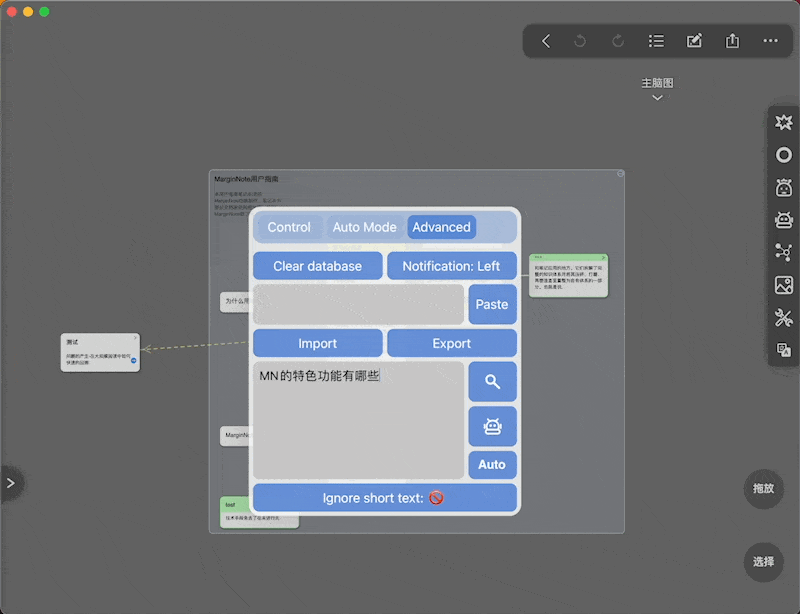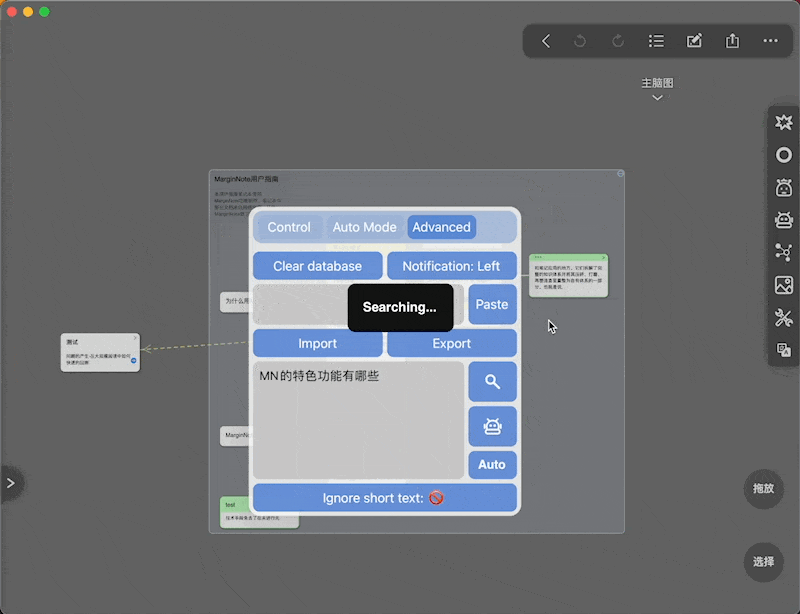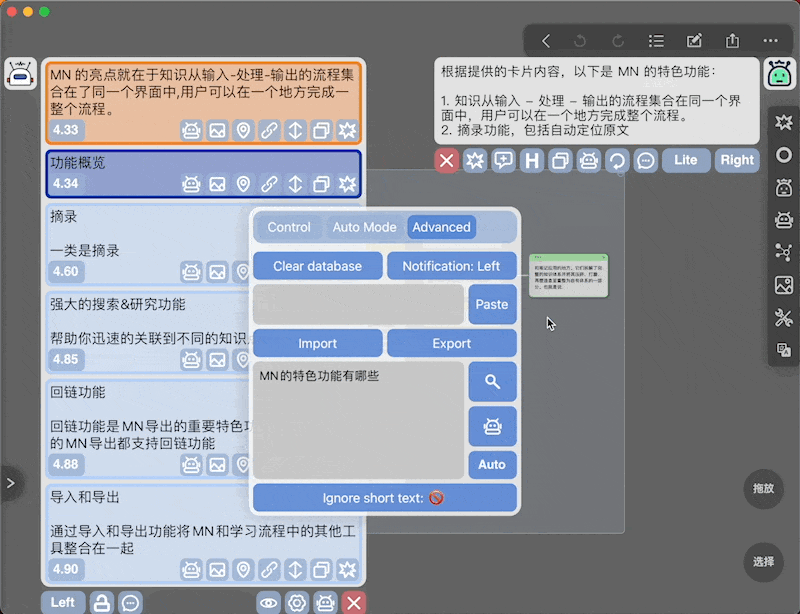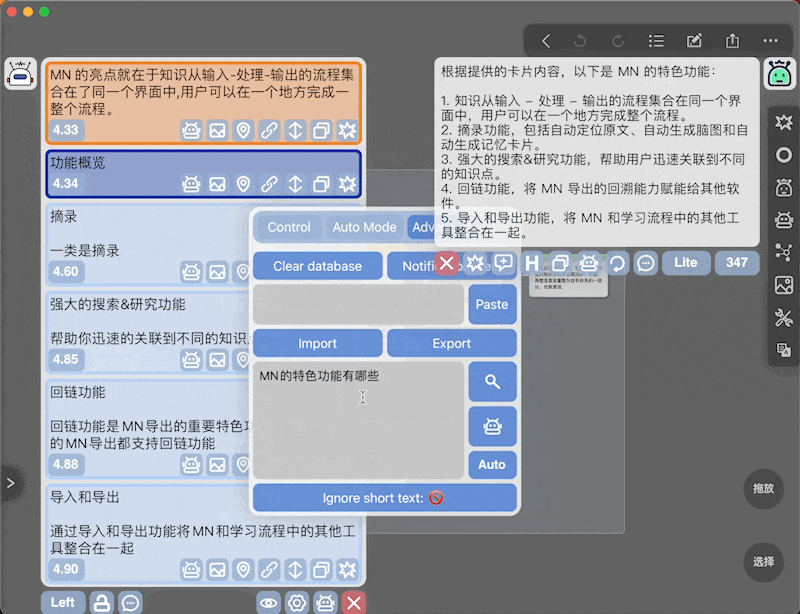
并且我们可以借助MN ChatGLM的连续对话能力,在当前上下文里继续和AI交流
五、锁定模式
-
另外为了满足对话场景的需要,还引入了锁定模式
点击
 后,即可进入锁定模式,自动模式会暂时禁用
后,即可进入锁定模式,自动模式会暂时禁用在这一模式下,允许移除部分卡片
这样就可以手动去掉一些不希望作为上下文的卡片
-
在锁定模式下,点击AI对话按钮将不再搜索卡片,而是直接基于已有卡片回答


六、其他设置
-
数据库清除
提供了五种范围的内容清除
-
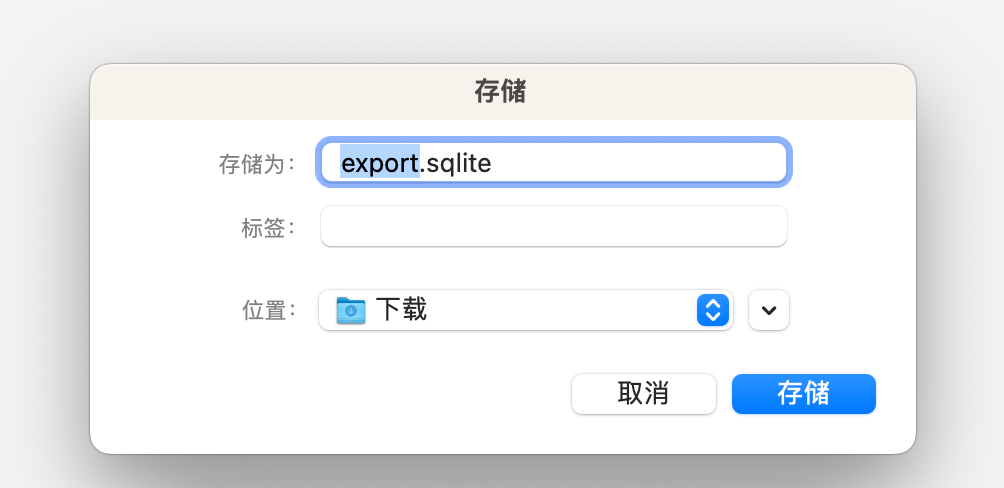
数据库导入导出
由于创建向量数据库本身是个消耗时间的过程,又无法直接依靠iCloud同步,因此直接导入其他设备上本插件创建的数据库,可能会是比较快的方案
导出:得到的是一个sqlite的文件,导入数据库时也是导入这个文件
注意有时候更新会导致数据库被删除,所以建议有空就导出一个备份
-
通知位置
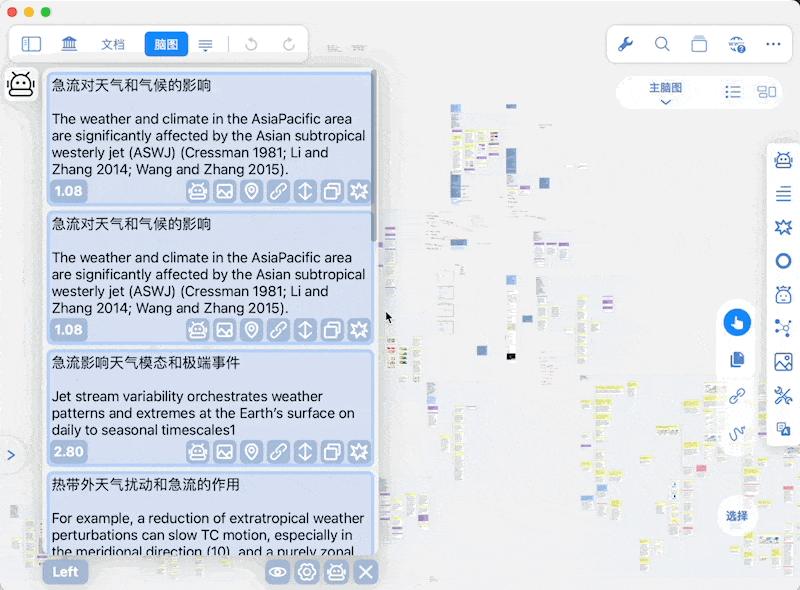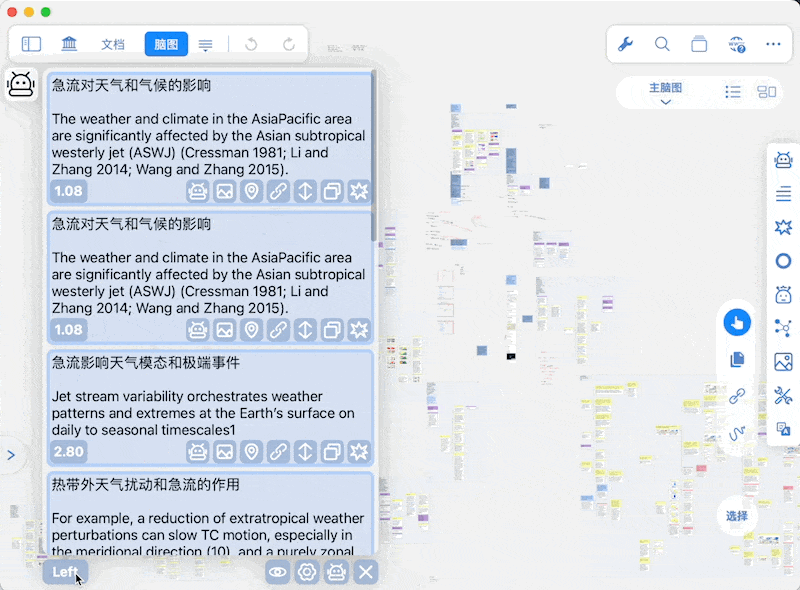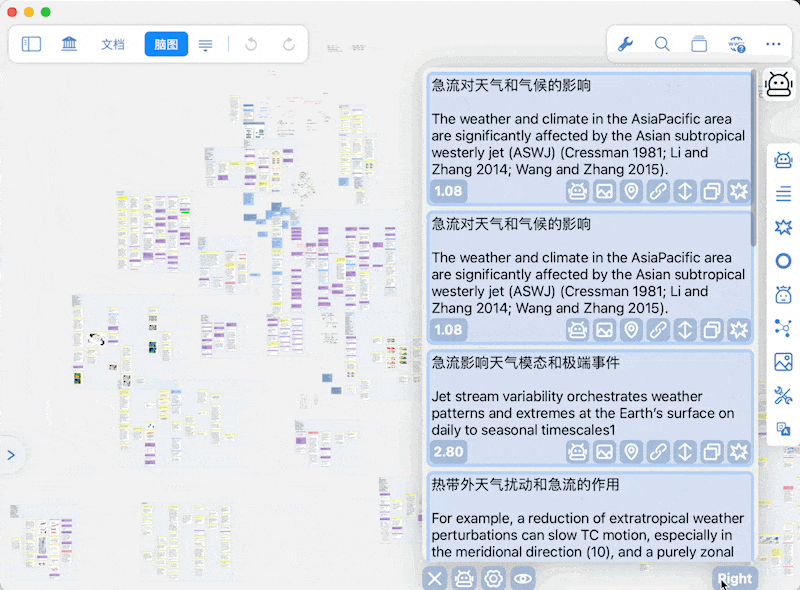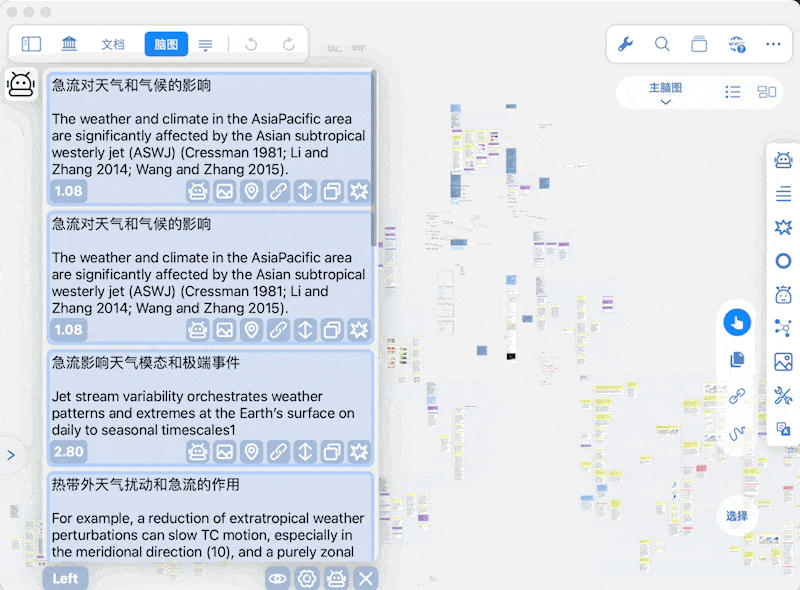
-
阈值与显示条目
Distance threshold:判断是否相关的阈值,代表着两张卡片在空间上的距离,距离越小代表关系越强,因此这里的距离阈值越小代表判断相关的标准更严格
Result length:要显示多少条相关的卡片,前提是确实有这么多相关卡片。同时点击列表底部“More”按钮时额外显示的条目也由这里控制
七、常见问题
-
插件的哪些功能需要联网
- 创建/修改向量数据库时
- 自动模式下,选中卡片未被向量化时
- 搜索/问答模式下,需要将输入文本转化为向量才能匹配相关卡片
-
性能消耗如何?
- 性能消耗主要发生在搜索相关卡片的过程中,插件需要遍历指定范围内的每张卡片,并进行排序,才能最终生成卡片列表。搜索的范围越小,卡片越小,速度越快。如果你设定的搜索范围内有几千张向量化后的卡片,那么处理是需要一点时间的,具体时间取决于设备性能,搜索过程MN会卡住(两个1024维数组计算距离的操作执行上万次对性能的要求是能明显感觉到的)。
- 搜索的速度与缓存情况有关,冷启动时,数据都存储在硬盘中,读取较慢,但是在此过程中会把读取过的部分缓存到内存中。因此同样的卡片,第一次搜索时速度较慢,第二次开始被缓存过的部分搜索起来速度会快个几倍。
-
文本长度限制?
根据官方API说明,每段长度不得超过512字符
本插件的方案是对卡片的每段文本都执行向量化
如一张卡片有标题、摘录文本、3条评论,则一共需要执行5次向量化
因此注意每个条目不超过512字符就行,如果超过了可能会直接进行截断处理