MarginNote-Zotero学术工作流
这篇文章从“五种特性”的角度向大家介绍我的Marginnote-Zotero学术写作工作流,Applescript脚本、Alfred插件以及Obsidian插件是连通这两样工具的桥梁。
我希望从阅读、摘录、整理、成稿的整个环节全面补齐Marginnote在学术写作方面的短板。有了Zotero的支持,Marginnote不再是无根之木、无源之水,而是处处有据可考、处处有证可依的内容发掘工厂与思维孵化器。。你可以在一个笔记本中绑定多篇pdf进行专题性的文献阅读,也可以先使用子脑图划分不同出处的摘录,最后再通过引用卡片,在新的框架中迭代整合,进而获得获得系统性的梳理文稿。
过去的“边写边引”变成“自动识别引用”、“自动生成参考文献列表”,阅读时分神来回切换阅读器和文献管理工具进行参阅和引用彻底成为过去式。以Markdown为载体的写作更专注于内容,结合Obsidian的Pandoc插件一键完成优雅的终稿排版。
 所需附件
所需附件
- Alfred脚本:Pandoc-Suite.and.BibTeX-Zotero-Citation-Picker.for.Academic.Writing.in.Markdown.v5.1.alfredworkflow (361.9 KB)
- AppleScript脚本:子脑图摘录批量插入引文标识.scpt (19.0 KB)
- 论文csl样式模板(示例):chinese-std-gb-t-7714-2015-author-lowercase_all_author.csl (9.4 KB)
一、非线性写作
此特性依赖于Marginnote的基础视图“ 脑图画布 ”作为组织思维的看板,以及两个基础功能“ 摘录 ”、“ 笔记卡片 ”。
卡片本身来自于文献摘录,也可以是手动新建的内容,承载着“概括规律”、“发现异常”、“评论观点”、“对比分析”的思维活动。
工作流建议
- 逐篇阅读文献并摘录:将“摘录设置”-“自动插入位置”设置为“分组(按文档)”,新摘录将自动插入文献PDF名称的父节点下,注意让这个节点作为游离的根节点,推荐切换为框架分支样式优化脑图的空间利用。
- 文献根节点升级为子脑图作为GTD完成状态:摘录完一篇文献后,点按文献摘录根节点,上弹菜单中点按“坍缩为子脑图”,继续阅读下一篇文献
操作步骤
一句话解释:从文献中摘录重要内容,在一张画布上拖动笔记卡片,重排摘录卡片,书写概括卡片、观察卡片和分析卡片作为文献笔记,在梳理内容中整理自己的文章框架,完成综述初稿

二、迭代重组
此特性依赖于Marginnote的两个基础功能“ 引用卡与原始卡 ”、“ 子脑图(旧名:灵感盒) ”,这两个功能的具体细节参见此篇功能介绍帖。
工作流建议
- 摘录完全部文献,一个个子脑图按照文献名称将摘录划分在不同空间,不用担心发生来源出处的混杂。
- 通过引用功能将值得进一步分析研究的笔记拖放至主脑图画布上,改变父子层级结构,梳理出自己待研究问题的叙述框架。
操作步骤
一句话解释:将来自不同文献的摘录卡片通过拖动引用到同一个画布上,根据摘录的具体内容梳理父子关系,制作新的思维导图,同时任何对摘录卡片的修改和补充都会同步到原始出处卡片中,不需要费心变更出处和新导图中的卡片内容,实现内容创作的迭代。
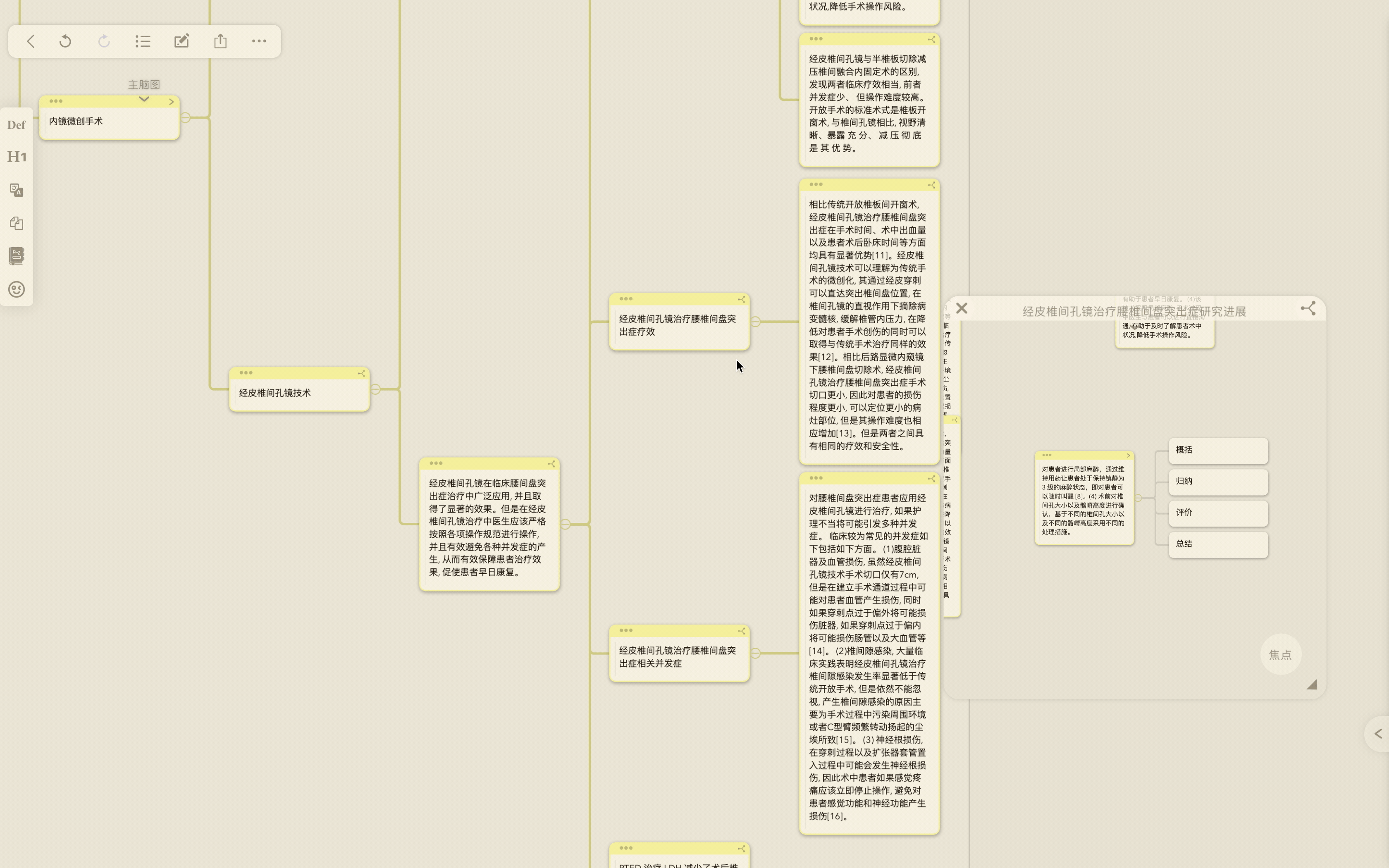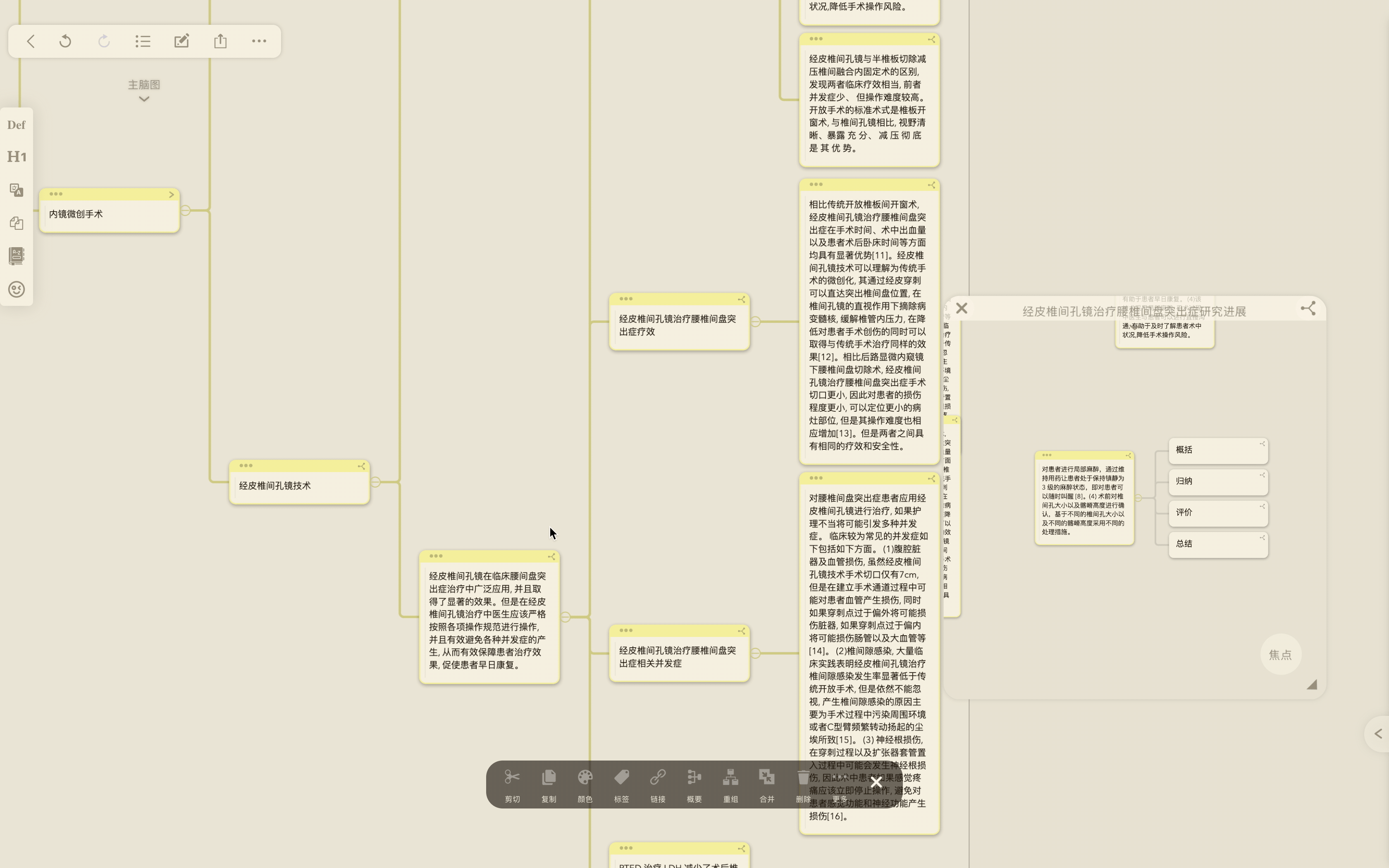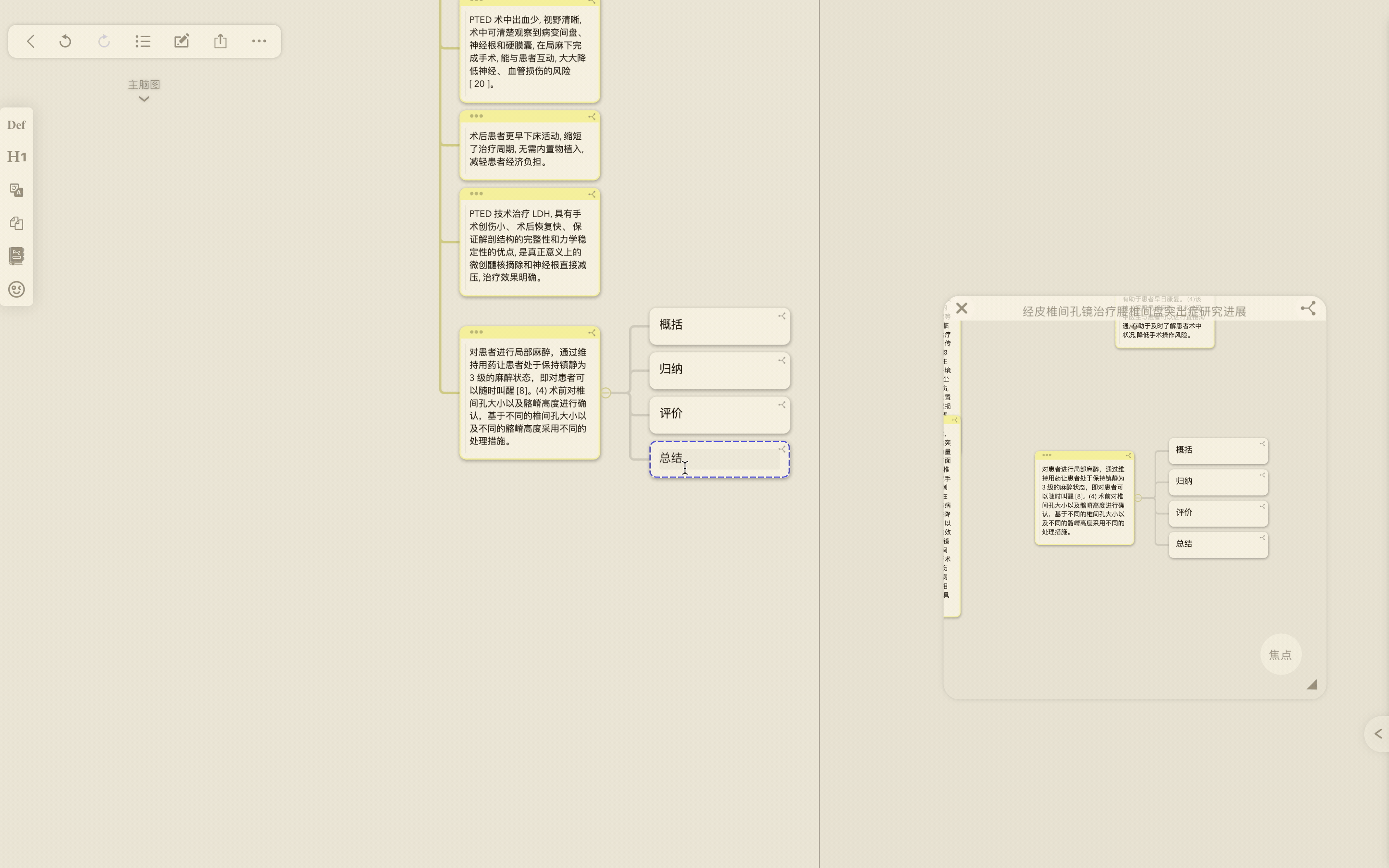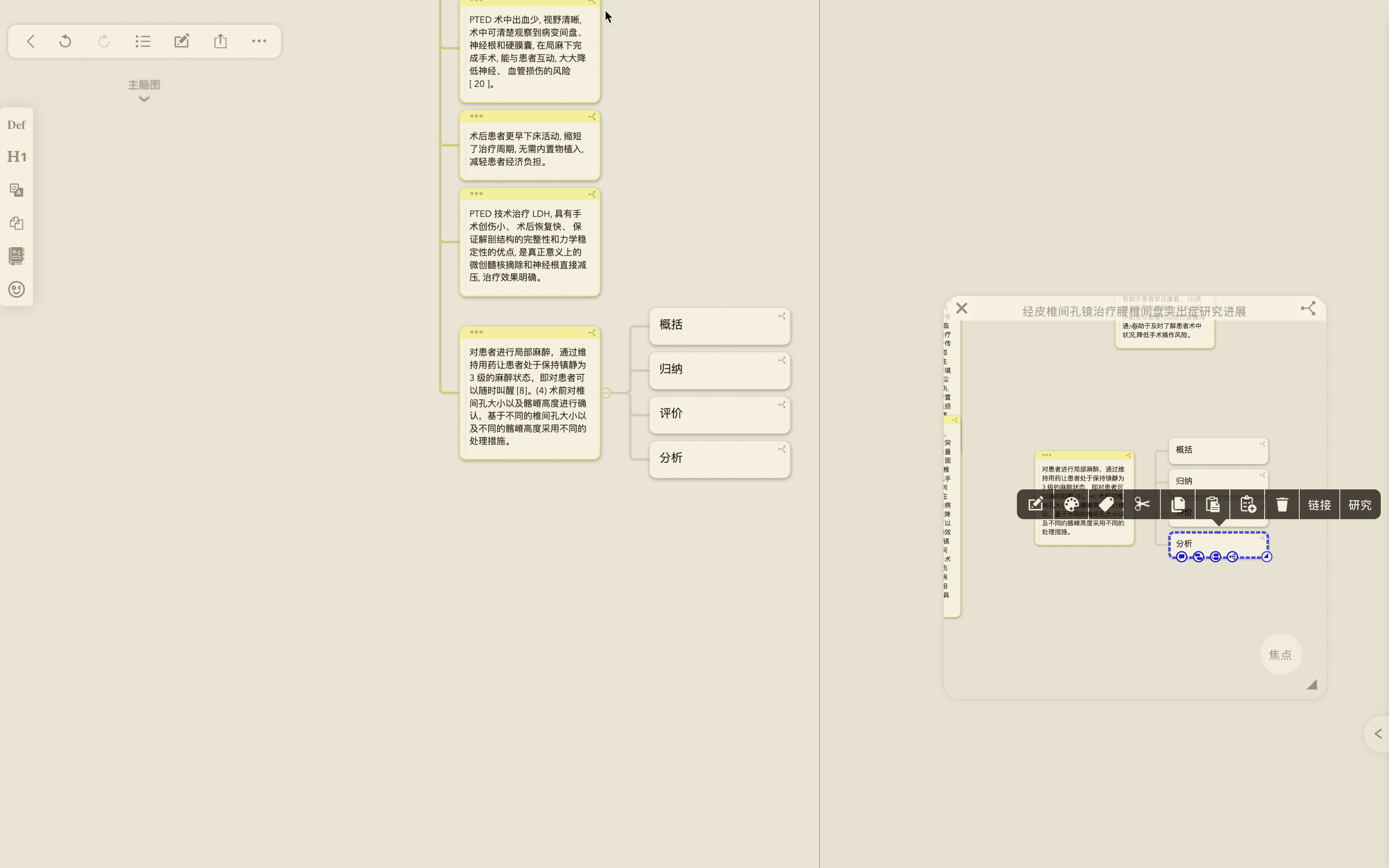
如果有我没解释清楚的地方,后文是我对引用卡片场景应用的进一步理解。
概念介绍
- 重组:是指对手中的信息进行重新编排、整理和总结,这在上一个部分中已经介绍了,论文写作的框架梳理就是通过非线性的写作来完成的。
- 迭代:是指在上下文的变更中保持知识生长的连贯性。
- 迭代重组:是指在重新构建新框架的同时,保持卡片信息的同步溯源。
智识的成长具有连贯性
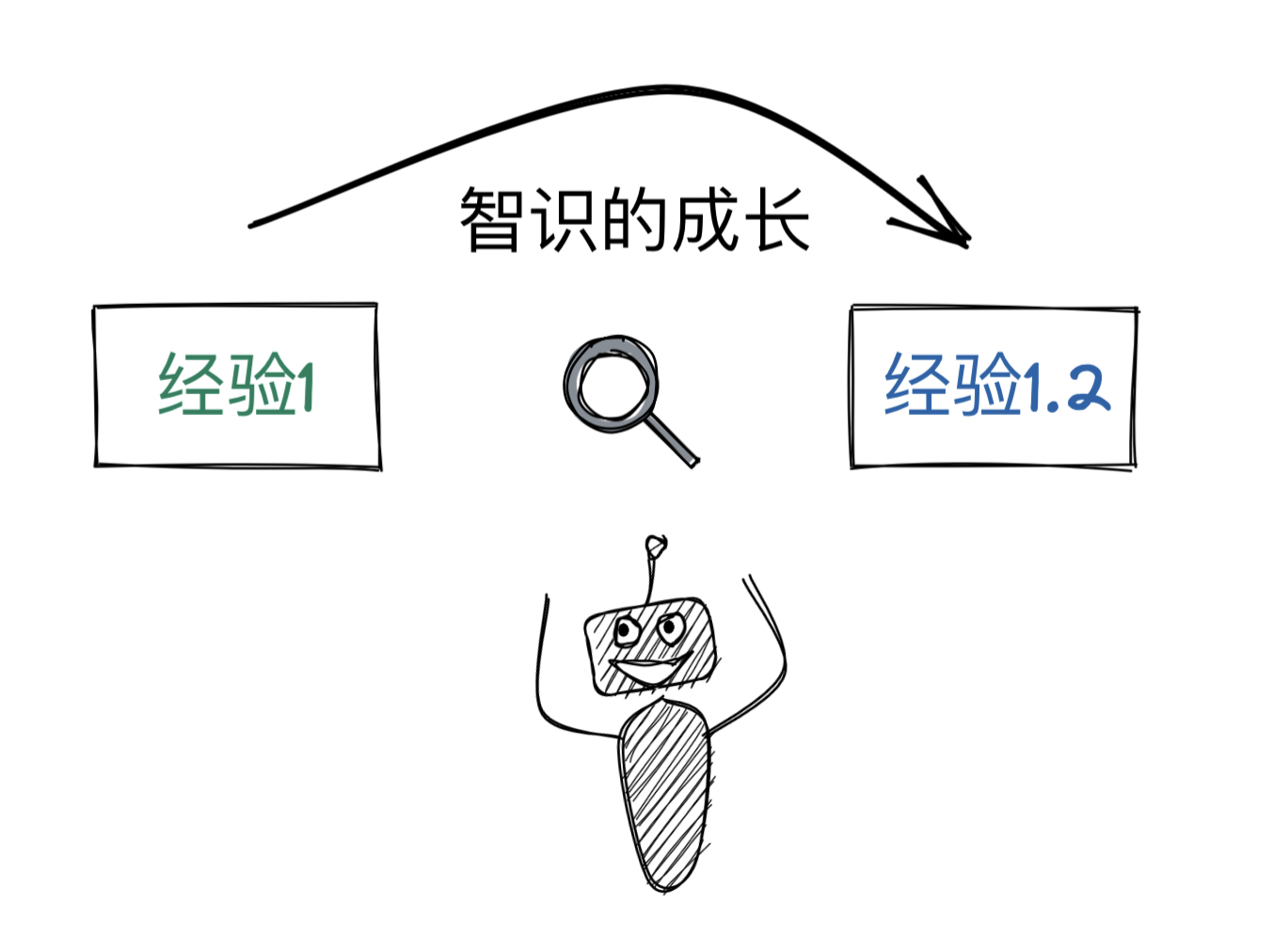
很多时候我只是记录下经验或者思维的片段,一旦把它们迁移到新的上下文中,可能就刷新了认知,需要对以前的记录进行修正、精简,或者补充新内容,这就是智识成长的过程。
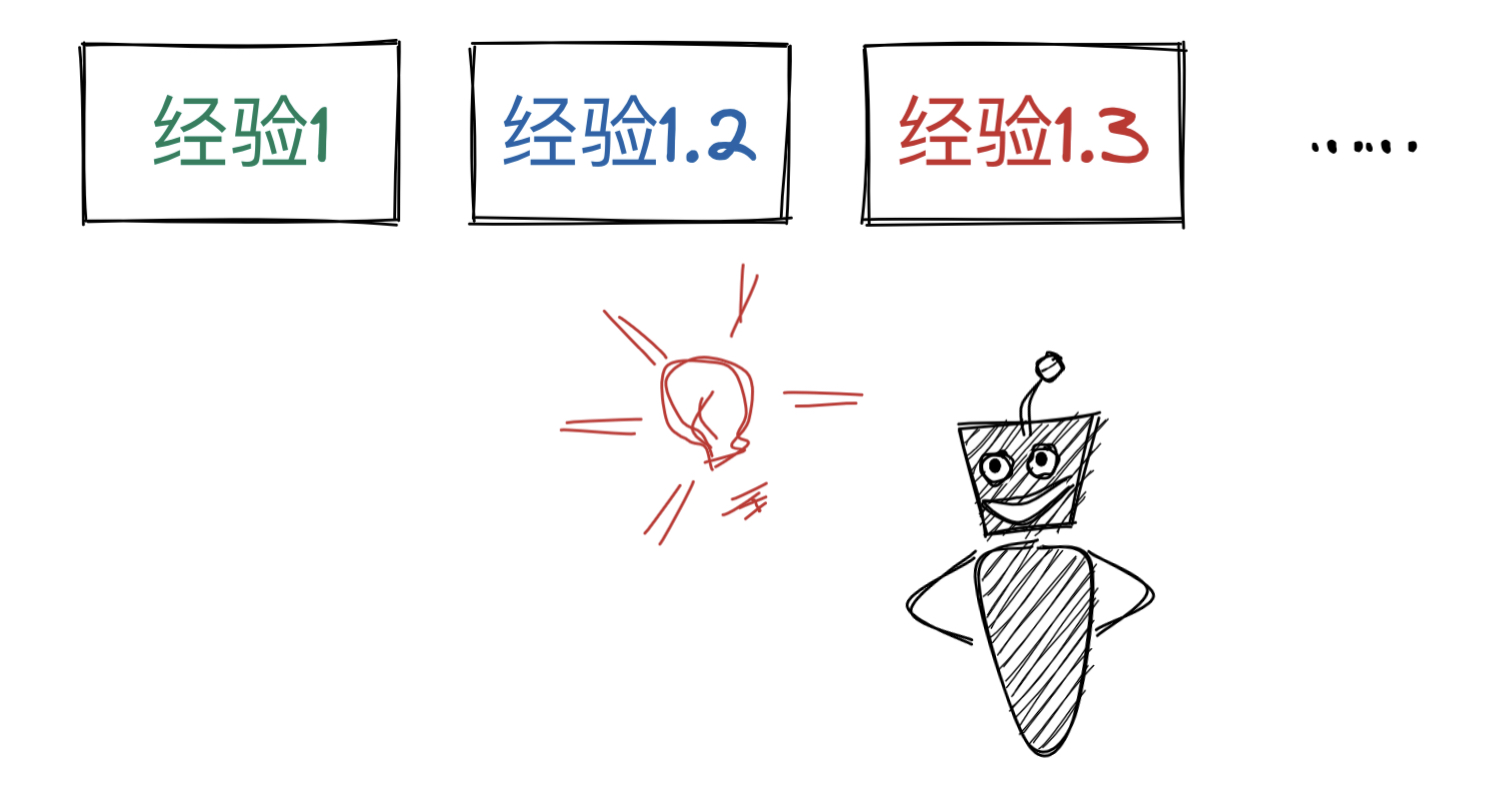
但翻找东西总是耗费精力的,为了避免当下某些观察和经验的流失,我可能会直接另起一个“炉灶”来保存刚捕获的新认知,这也是很多人会采用的日志式工作法。
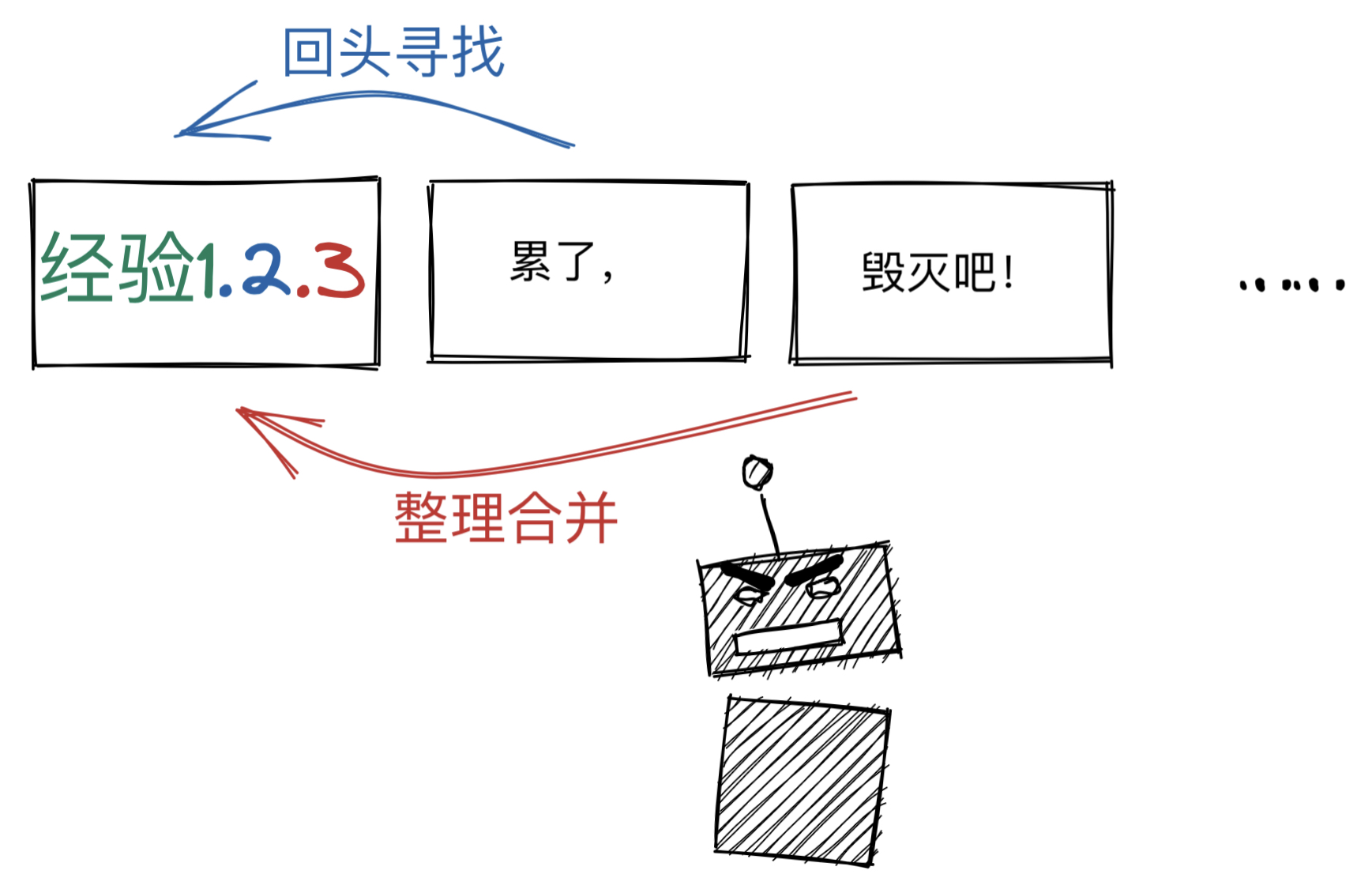
那么,请考虑一下“如果我现在记录的东西和以前记录的东西有重合怎么办?”。
日志工作法看起来打消了这种顾虑,因为另起炉灶确实很好地减轻了回顾总结的负担,我可能会觉得把注意力放在最新一个版本的内容就好了,但这种方法实际上没有回答“智识成长连贯性断裂与丢失”的问题。

经验是在记录时的整个观察上下文中产生的,或许我的某些观点会在来改变,但这并不意味着过去的经验就可以彻底抛弃了,至少当时的背景是有价值的。
日志工作法容易让人产生误解,它鼓励人们把精力放在新版本内容的理念是正确的,但因为舍弃过去的部分总结,进而放弃了过去的整个上下文信息,那就因小失大了。
那如果有一种工具可以在不变动以往上下文的情况下,重新组织新内容呢?
你可能会说那不就是“复制黏贴”吗?
可是复制黏贴会带来很多个总结内容的版本,你仍然需要花一部分精力来管理他们,像是回到旧的上下文、找出需要改进的内容复制然后删掉、将复制的内容黏贴到新地方进行修改和增补等。
看来我需要的不只是一种内容变更的版本管理工具,它除了支持内容的重构,更需要一种“溯源同步”的特性。
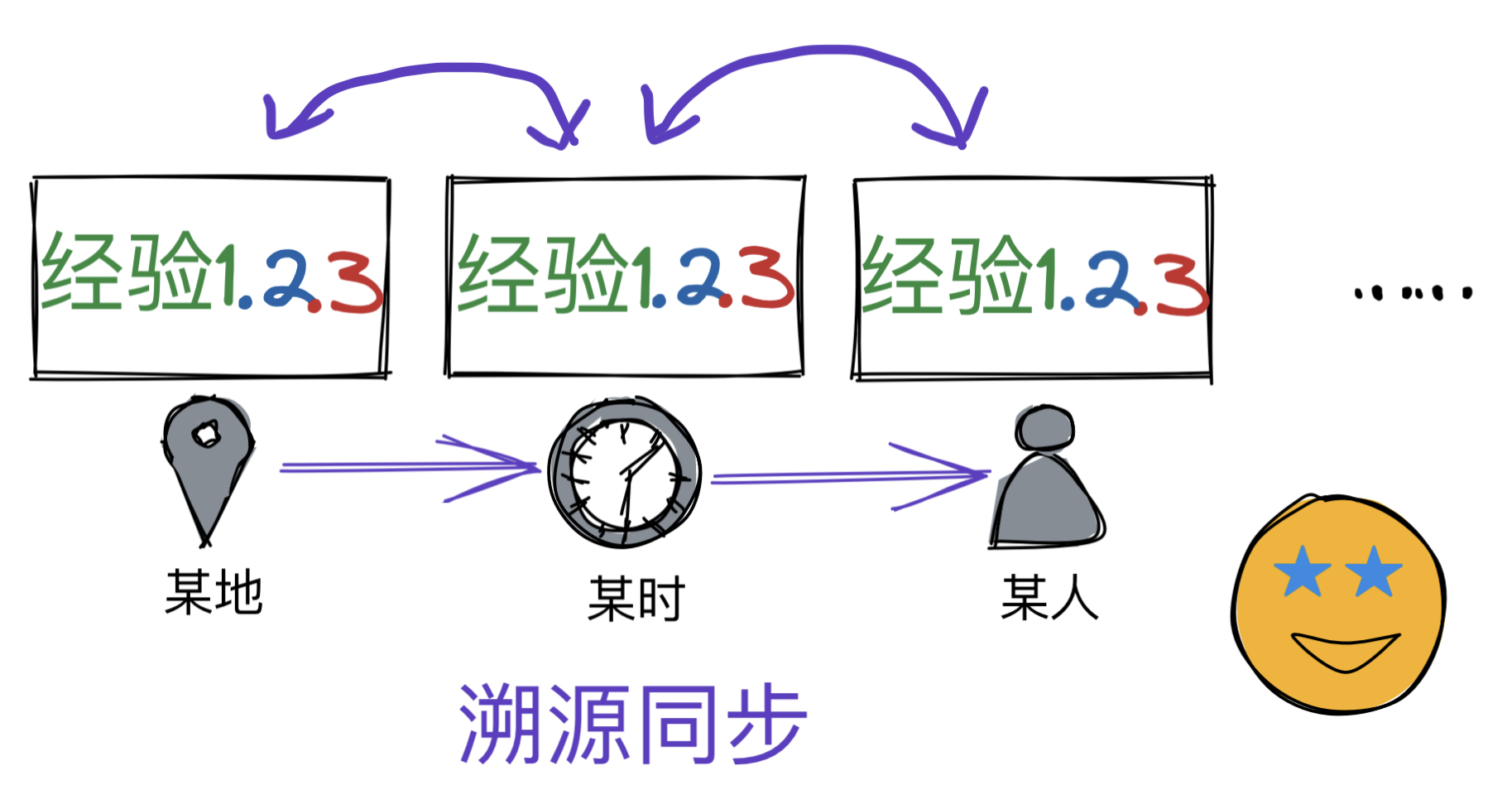
这个工具就是Marginnote的引用卡与原始卡功能。
三、引用皆有出处
此特性依赖Marginnote的 焦点导出功能 、 iThoughts 将Marginnote导出的思维导图初稿转换为Markdown文稿,以及 Alfred插件 获取文献标识符,作为沟通Marginnote与Zotero的桥梁。
手动获取参考文献列表的关键“钥匙”
如果一个人开始纠结“引用的管理”,那么Ta肯定是进入学术写作的领域了。
现实中可以看到很多论文在文末都附有参考文献列表,因为每一篇标准论文稿都需要遵循这样的学术规范。
但文字输出方面我总是更倾向于使用Markdown,相比重型的字处理工具Word,Markdown是一种更优雅的写作方案。
我通过iThought将Marginnote导出的思维导图转换为Markdown文稿,接着在Obsidian中对文稿进行内容方面的排版,经过这个步骤,由笔记卡片构成的层级信息结构被整理成更符合文章的形式。(iThought的免费替代方案见这篇文章)
那么,“Markdown文稿如何转换成通用的标准论文稿?”,或者说,“Markdown如何在文末生成参考文献列表?”
这里推荐阅读这篇文章:使用Markdown搭配Pandoc撰写学术论文的详细指南,你会了解到“citekey”这个概念,然后你就会知道我们只需要在Markdown中插入citekey标识符,接着在Markdown转Word的过程中,转换工具就会知道如何将Markdown中的引文与文献管理工具中的条目一一对应,最后生成自动生成文末的参考文献列表!
但是,“用于生成引用的元数据又是从何而来的呢?”
这个问题很简单。
首先,我们需要从在线的文献数据库获得文献元数据储存于Zotero(推荐Zotero的浏览器插件“Zotero Connector”)。
然后,通过Alfred插件获取citekey至剪贴板,即可粘贴至任意文本框。
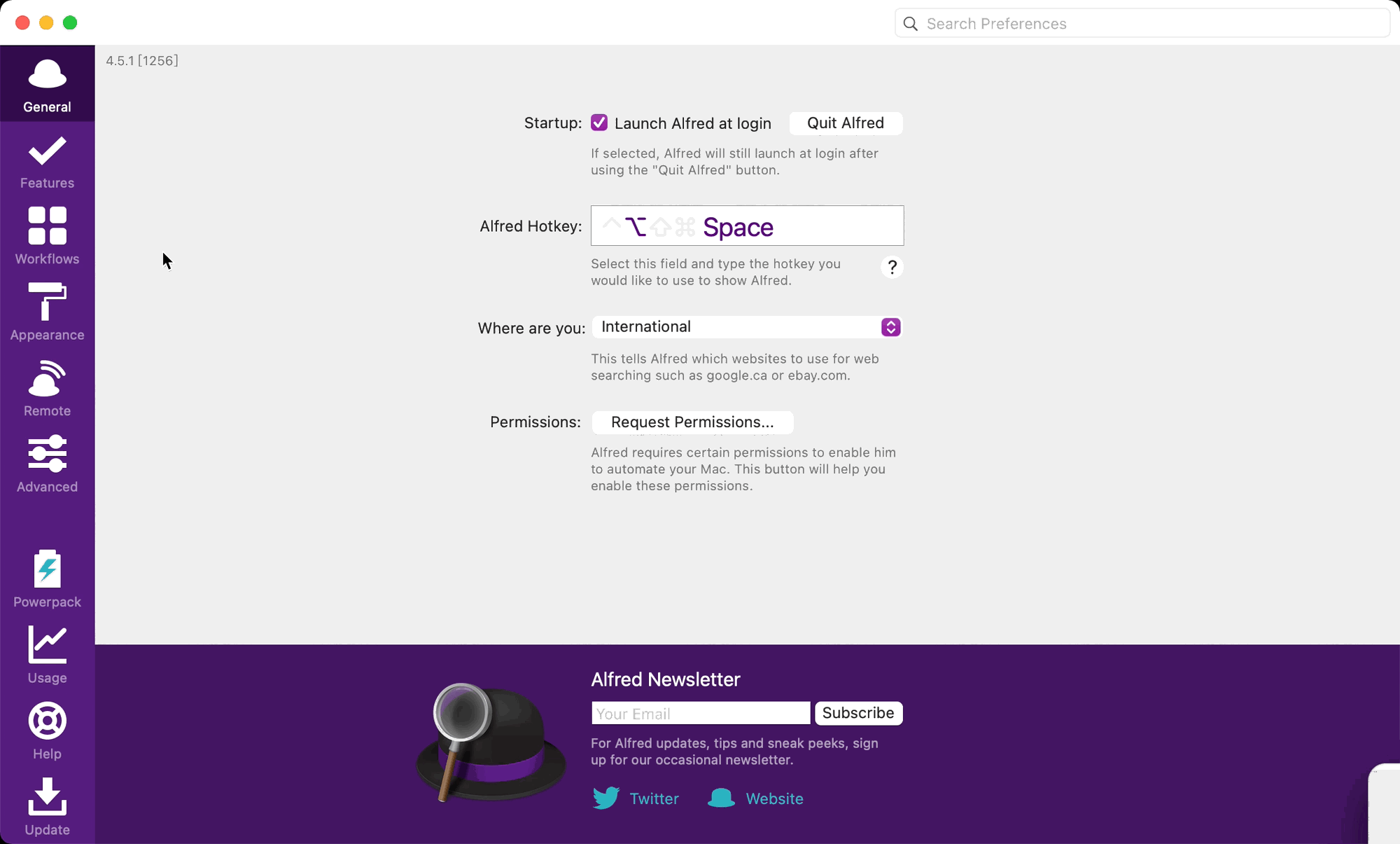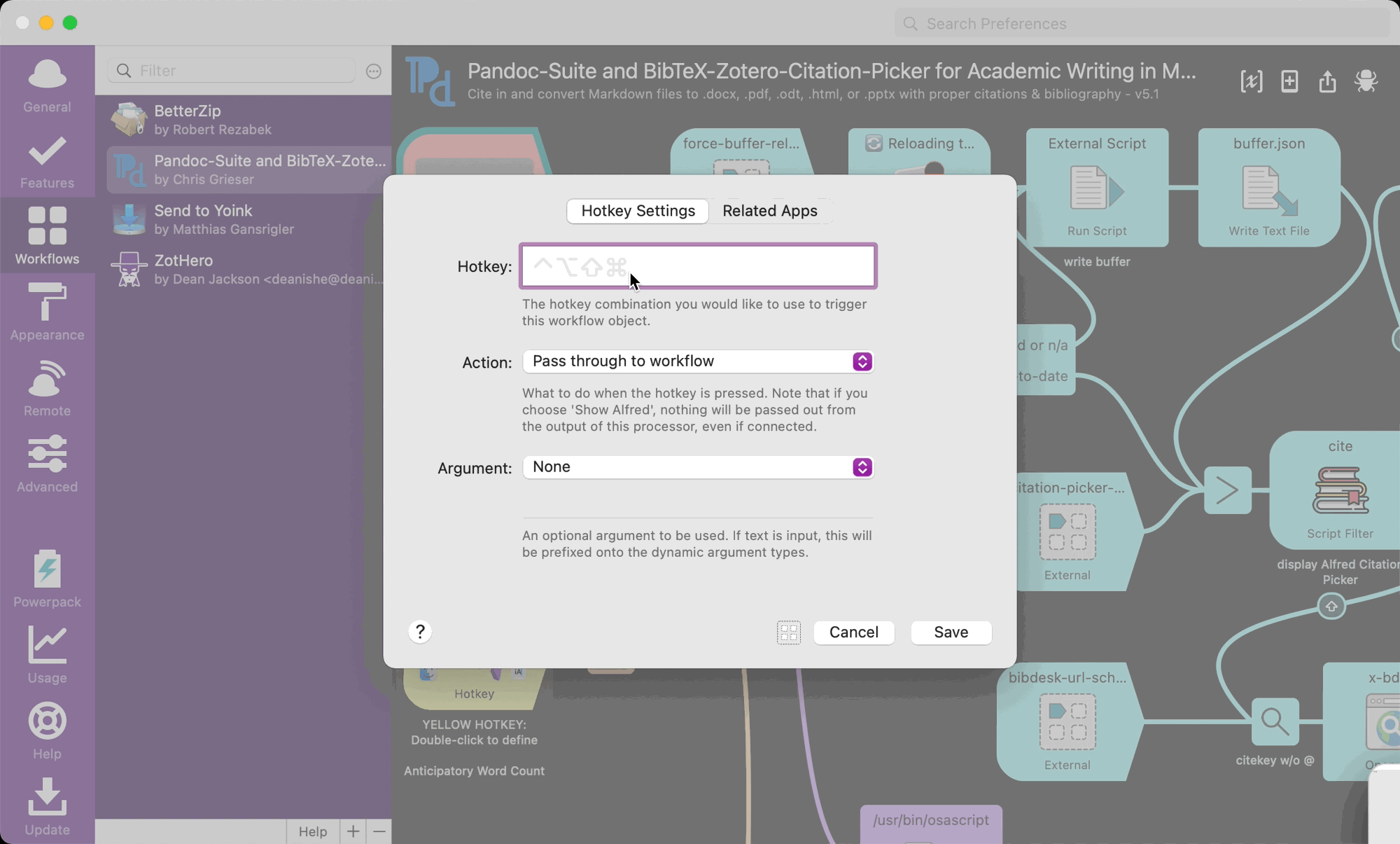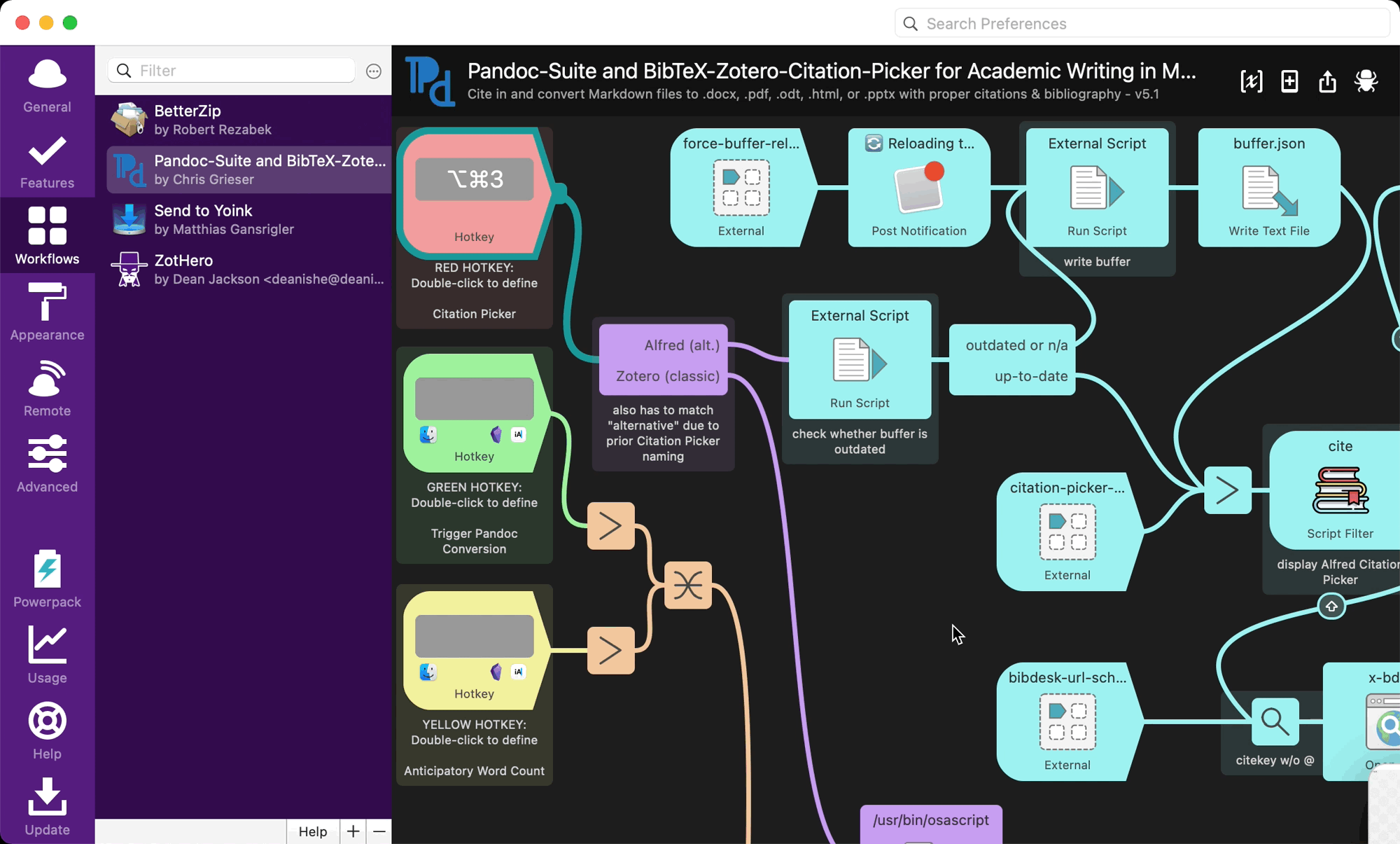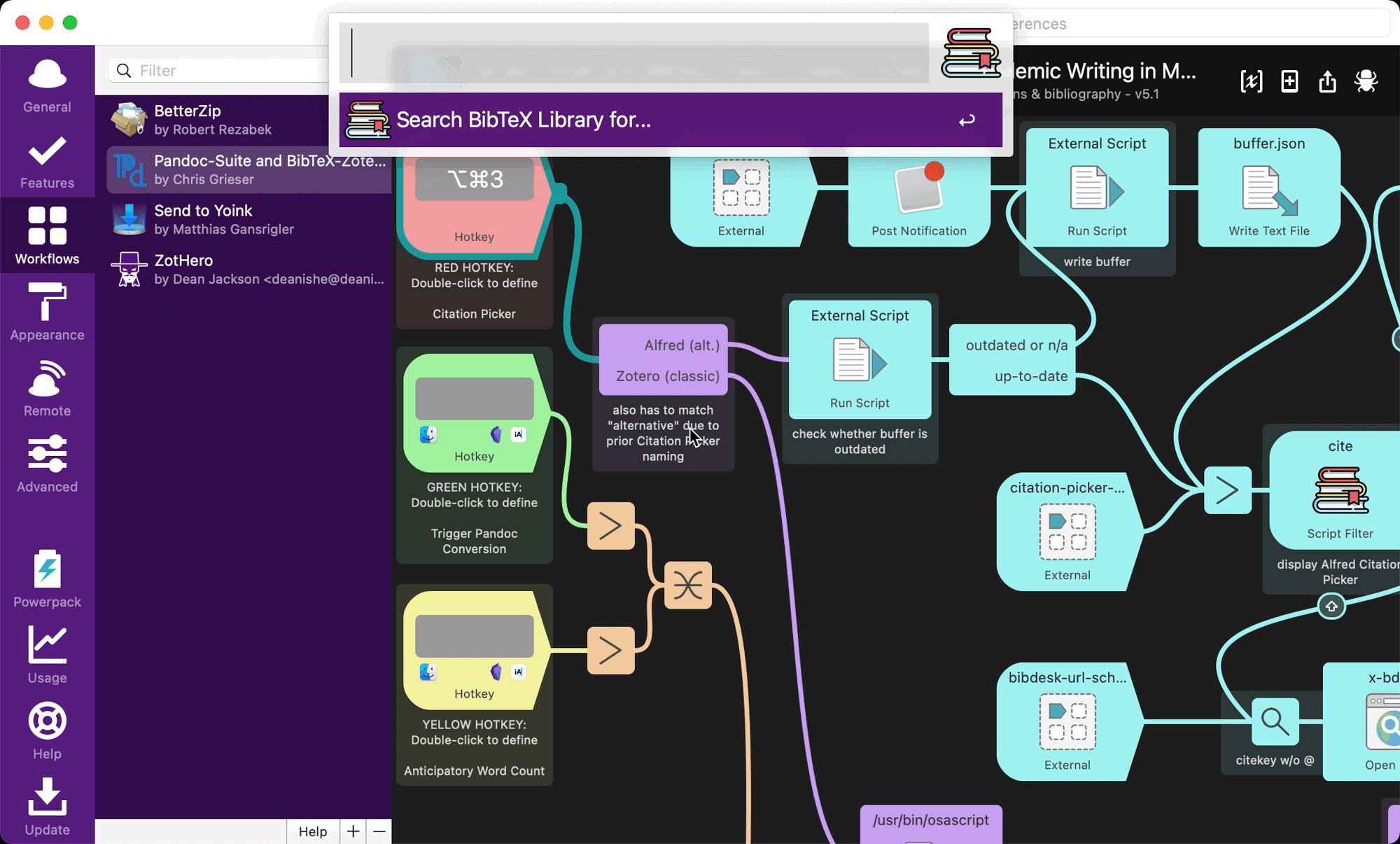
Alfred插件配置
- 快捷键:
- .bib文献库文档的路径:

操作步骤
一句话解释:通过Alfred脚本在文献阅读器Marginnote与文献管理工具Zotero之间实现元数据通信,“参照文献”与“行文输出”两个环节不再割裂,“阅读”与“写作”彻底融为一体,用于自动生成综述结尾的参考文献列表,写作者只需专注于内容的创作过程。
- 按下配置好的快捷键(
 option+command+3请跟我设置一样,否则需要自行改动脚本)通过Alfred插件获取citekey插入文本框
option+command+3请跟我设置一样,否则需要自行改动脚本)通过Alfred插件获取citekey插入文本框
- 将论文的思维导图初稿通过焦点导出为mindmanager格式,使用iThoughts进行转换, 注意 :
- 首先,iThoughts转换Markdown时如何选择标题数目取决于你的论文体裁,我在Marginnote中写作初稿时是按照最多4级标题的框架来整理,因此设置时选择4。
- 然后,这一步推荐在完成特性四步骤的批量插入citekey后进行


四、打破“边写边引”的魔咒
此特性依赖于我的 Applescript脚本 。
匹配引用的分神问题
现在你知道了只要有citekey,就能生成标准化的论文稿。
那么,“这个过程能不能自动化呢?”。
这个问题就不简单了,参考这篇知乎问题写学术论文时需要引用大量论文,但最后需要花费大量时间匹配引用,看完大部分回答,你会发现“边写边引(cite as you write)”的原则至今仍然是学术写作的铁律。
因为实在厌烦了写作时来回切换阅读器与文献管理器的窗口,也为了解决分神的问题,我写了一个Applescript来给Marginnote中的文献摘录批量添加citekey,希望可以打破“边写边引”的魔咒。
Applescript脚本配置
- 前提要求A:文献pdf的文档名称是文献标题,或者尽量包括标题关键词(必须,否则无法读取到.bib文献库中的对应数据)
- 前提要求B:遵循非线性写作、迭代重组的“工作流建议”,将文献pdf名称的根节点坍缩为子脑图,划分不同文献来源的摘录(必须,AS脚本即是根据子脑图进行批量添加)
- 前提要求C:遵循迭代重组的“工作流建议”,将子脑图内的摘录通过引用的方式拖动到主脑图。(非必须,也可以批量加完了标识符再拖出来,推荐先引用、梳理完你的论文结构,再进行批量插入citekey,主脑图的卡片会同步子脑图中的原始卡)
操作步骤
一句话解释:通过Applescript脚本调用Alfred插件来批量获取Zotero中的文献元数据,并且识别综述草稿正文中的摘录内容,在末尾批量插入citekey标识符,后续自动生成综述结尾的参考文献列表
![]()
![]()
![]() 运行前务必对当前笔记本进行备份
运行前务必对当前笔记本进行备份 ![]()
![]()
![]()
五、手稿自动排版
此特性依赖于Obsidian的Pandoc插件。
Markdown导出Word终稿
借助Obsidian的Pandoc插件,可以将Markdown文稿转换为Word文稿,至此写作流程也就来到了最后一个环节。
除了基础的标题排版样式,Pandoc也提供一些高阶命令来为你的论文生成目录、标题、交叉引用超链接,甚至可以套用指定的Word模板。
Pandoc插件配置
- 首先在Obsidian中安装并启用pandoc插件
- 然后进入Pandoc插件配置页面,设置好“Export folder”(导出文件夹)、“Export file from HTML or Markdown”(选择Markdown)
- 最后在“Extra Pandoc argument”黏贴下列代码:
- 基础代码:
- –citeproc:表示导出时生成参考文献列表
- –metadata bibliography=/Users/【你的Mac用户名称】/Documents/我的文库.bib:从你的Zotero导出文献库,选择Better BibTex格式,即可获得.bib文档,这里换成你自己的路径
- –csl=/Users/【你的Mac用户名称】/Documents/chinese-std-gb-t-7714-2015-author-lowercase_all_author.csl:从网上下载的csl样式,根据你导师要求或者要投的期刊要求选择
- 进阶代码:
- –metadata reference-section-title=“参考文献”:在参考文献列表前生成一个标题名为“参考文献”
- –toc:根据标题框架为你的文献生成目录
- –number-sections:为生成的目录自动编号
- –metadata link-citations=true:将序号脚注转换为文档内超链接,点击可跳转至论文末尾对应的参考文献条目
- GIF中的配置例子(注意所有指令前都是
 两个短横杠 ,论坛显示成了一个长横杠):
两个短横杠 ,论坛显示成了一个长横杠):
- 基础代码:
–toc --number-sections --metadata bibliography=/Users/【你的Mac用户名称】/Documents/我的文库.bib --csl=/Users/【你的Mac用户名称】/Documents/chinese-std-gb-t-7714-2015-author-lowercase_all_author.csl --metadata reference-section-title=“参考文献” --metadata link-citations=true --citeproc
操作步骤
一句话解释:在Obsidian中安装Pandoc插件,运行指令读取Markdown文稿中行文框架,生成排版完善的Word终稿。


